【数量化について】
多変量解析の「重回帰分析」「判別分析」「主成分分析」等は、量的データを扱う分析方法であるが、いつも量的データの形で標本を得られるとは限らない。そこで、得られた質的データに適当な数量を与え、質的データを数量化することにより多変量解析が行えるようにすることを「数量化」という。
統計で扱うデータには、「量的データ」と「質的データ」があり、量的データは数値の間隔に意味を持つデータであるが、質的データはその間隔に意味はもたなく他のものと区別したり、順序を示したりするデータである。
![]()
![]() 量的データ
間隔尺度…絶対原点を持たない尺度データ
量的データ
間隔尺度…絶対原点を持たない尺度データ
比例尺度…絶対原点を持つ尺度データ
![]() 質的データ 名義尺度…分類を示すデータで大小関係に意味は持たない
質的データ 名義尺度…分類を示すデータで大小関係に意味は持たない
順序尺度…順序関係の大小に意味を持つデータ
通常質的データは計算することができないので、そのまま統計分析をすることはできない。そこで、質的データを目的に合うように最適な数値に置き換えて数量化することにより、多変量的な解析ができるようにするのが数量化であり、「重回帰分析」「判別分析」「主成分分析」に対応するのが、「数量化Ⅰ類」「数量化Ⅱ類」「数量化Ⅲ類」である。
【5】数量化Ⅰ類
数量化Ⅰ類は、量的データを分析する重回帰分析に対応する質的データを分析する方法である。重回帰分析では、量的データである説明変量から、量的データである目的変量を予測した。これに対し数量化Ⅰ類では、アイテム・カデゴリと呼ばれる質的データを得て、この値から量的データである外的基準(目的変量に対応する)を得る方法である。
アイテム(項目)とは質問事項のようなものであり、カテゴリとはその回答のようなものである。
アイテムは、例えば「貴方は英語が好きですか?」のようにアンケートの質問事項のように与えられ、カテゴリは「はい/いいえ」のように分類で与えられる。この質的データであるカテゴリから外的基準と呼ばれる量的データを予測するのが数量化Ⅰ類という分析方法である。
〈1〉予測線形式を求める。
[1]アイテムが1つ、カテゴリが2つの場合を考える。
|
標本No |
外的基準 |
ア イ テ ム |
|
|
カテゴリ1 |
カテゴリ2 |
||
|
1 2 n |
y1 y2 yn |
x11 x12 x1n |
x21 x22 x2n |
いま、外的基準として英語の点数(10点満点)、アイテムとして「英語は好きですか?」という質問事項、カテゴリとして「はい/いいえ」とする。
|
標本No |
外的基準 |
英語は好きですか? |
|
|
はい |
いいえ |
||
|
1 2 3 4 5 6 7 8 |
2 4 5 7 8 6 5 3 |
レ レ レ レ |
レ レ レ レ |
アンケートをとった結果、該当するカテゴリにレ印をつけて、上のような表を得たとする。
次に、カテゴリにおいて、該当があれば「レ」をつけたが、このままでは計算することができないので「該当有り…1」「該当無し…0」と置き換える。この置き換える変数のことを「ダミー変数」と言う。
![]() 1…アイテム(i)、カテゴリ(j)で該当有り
1…アイテム(i)、カテゴリ(j)で該当有り
ダミー変数(xij)
0…アイテム(i)、カテゴリ(j)で該当なし
このダミー変数を使用して、先ほどの表を数量化してみると
|
標本No |
外的基準 y |
英語は好きですか? |
|
|
はい (x1) |
いいえ(x2) |
||
|
1 2 3 4 5 6 7 8 |
2 4 5 7 8 6 5 3 |
0 0 1 1 1 1 0 0 |
1 1 0 0 0 0 1 1 |
アイテム・カテゴリの結果から、外的基準を求める予測式Yを考える。
Y=a1・x1+a2・x1 とすると
予測値は Y1=a1・0+a2・1
Y2=a1・0+a2・1
Y3=a1・1+a2・0
Y4=a1・1+a2・0
Y5=a1・1+a2・0
Y6=a1・1+a2・0
Y7=a1・0+a2・1
Y8=a1・0+a2・1
予測値Yiと実測値yi とのずれを小さくしたいので、最小2乗法を使って
∑(yi-Yi)2 を最小にすることを考える。
∑(yi-Yi)2 =(2-a2)2+(4-a2)2+(5-a1)2+(7-a1)2+(8-a1)2+(6-a1)2+(5-a2)2+(3-a2)2
= 4a12 + 4a22 - 52a1
- 28a2 + 228 =Gとおく
このGをa1a2 で偏微分し0とおいて、正規方程式を得ると
![]()
よって、予測式Yは、Y=6.5・x11 + 3.5x12 となる。
この式を使用することにより、アンケート結果から外的基準である英語の点数を予測するこ とができる。
[2]アイテムが2つ、カテゴリが2つの時
(1)アイテムが1つの時と同じように最小2乗法で予測式を求める。
今度はアイテムが2つ、英語と数学。カテゴリが2つ、好きと嫌いの場合を考える。
|
標本No |
英語の点数 y |
英 語 |
数 学 |
||
|
好き x11 |
嫌い x12 |
好き x21 |
嫌い x22 |
||
|
1 2 3 4 5 6 7 8 |
2 4 5 7 8 6 5 3 |
レ レ レ レ |
レ レ レ レ |
レ レ レ レ |
レ レ レ レ |
これをダミー変数を使用して書くと
|
標本No |
英語の点数 |
英 語 |
数 学 |
||
|
好き |
嫌い |
好き |
嫌い |
||
|
1 2 3 4 5 6 7 8 |
2 4 5 7 8 6 5 3 |
0 0 1 1 1 0 1 0 |
1 1 0 0 0 1 0 1 |
0 1 1 0 1 1 0 0 |
1 0 0 1 0 0 1 1 |
ここで予測式Yを
Y=a11・x11+a12・x12+a21・x21+a22・x22 とする。
アイテムが1つの時と同様にして
∑(yi-Yi)2 =Gとして、この式をa11・a12・a21・a22 で偏微分して0とおき、正規方程式を得る。
G=(2-a12-a22)2
+ (4-a12-a21)2 + … + (3-a12-a22)2
=228-50a11-30a12-46a21-34a22+4a11・a21+4a11・a22+4a12・a21+4a12・a22+4a112+4a122+4a212+4a222
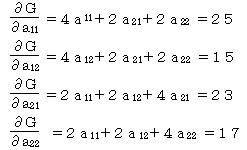
ダミー変数間で、x11+x12=1 x21+x22=1 となっているために、このままではaij を求めることはできない。アイテムが1つの時にはこの問題はなかったが、アイテムが2つ以上になると、この問題は必ず発生する。このため、通常第2アイテム以降の第1カテゴリを0として計算する。
条件 ai1=0 (i=0,1,2,…) としてaijを求める。
a21=0 とすると
4a11+2a22 =25
4a12+2a22 =15
2a11+2a12 =23
2a11+2a12+4a22 =17
これを解くと
a11 = 7 a12 = 4.5
a22 = -1.5
よって予測式は
Y = 7・x11 + 4.5・x12 - 1.5・x22 と求められる。
(2)行列を使用して、予測式を求める。
いま、各カテゴリについて行列を作成し、Dとすると
x11 x12 x21 x22 Y
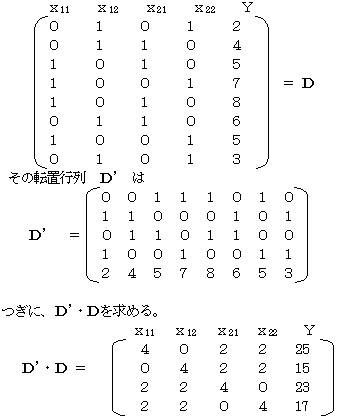
これをみると、各行がそのまま正規方程式の係数になっていることが分かる。これから
![]() 4a11+2a21+2a22 =25
4a11+2a21+2a22 =25
4a12+2a21+2a22 =15
2a11+2a12+4a21 =23
2a11+2a12+4a22 =17
の方程式を得て、a21=0として、aijを得ることができる。
(3)行列を使用して、予測式を求める。
(2)の方法では、行列から正規方程式を得てa21=0として、方程式を解きその係数aijを求めたが、最初に行列のa21成分を取り除いたダミー行列を考えて、直接aijを 求める。
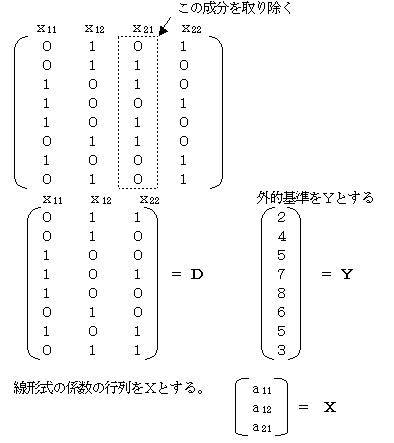
この時、X
は、 X=(D’・D)-1・D’・Y で求めることができる。
一般の場合でも、第2アイテム以降の第1カテゴリを除いた行列から、線形予測式の係数を求めることができる。
〈2〉カテゴリ数量の基準化
通常線形予測式を求めるにあたり、第2アイテム以降の第1カテゴリに対応する数量
ai1 =0 (i=2,3…)として求めているので、第2アイテム以降の第1カテゴリ
係数は常に0となる。そこで各アイテム内のカテゴリ数量が0になるようにカテゴリ数量を変換する。これをカテゴリ数量の基準化という。こうすると、第2アイテム以降の第1カテゴリの係数を他のものと同じように得ることができる。
|
標本No |
英 語 |
数 学 |
実測値(y) 英語の点数 |
予測値(Y) 英語の点数 |
||
|
好き |
嫌い |
好き |
嫌い |
|||
|
1 2 3 4 5 6 7 8 |
0 0 1 1 1 0 1 0 |
1 1 0 0 0 1 0 1 |
0 1 1 0 1 1 0 0 |
1 0 0 1 0 0 1 1 |
2 4 5 7 8 6 5 3 |
3 4.5 7 5.5 7 4.5 5.5 3 |
予測値
Y は予測式 Y = 7・x11 + 4.5・x12 - 1.5・x22 から求めた値上の表で、各カテゴリについてaij・x11を求めていくと
|
標本No |
英 語 |
数 学 |
実測値(y)英語の点数 |
予測値(Y) 英語の点数 |
||
|
x11 |
x12 |
x21 |
x22 |
|||
|
1 2 3 4 5 6 7 8 |
0 0 7 7 7 0 7 0 |
4.5 4.5 0 0 0 4.5 0 4.5 |
0 0 0 0 0 0 0 0 |
-1.5 0 0 -1.5 0 0 -1.5 -1.5 |
2 4 5 7 8 6 5 3 |
3 4.5 7 5.5 7 4.5 5.5 3 |
|
合計 |
28 |
18 |
0 |
-6 |
40 |
40 |
|
合計 |
46 |
-6 |
40 |
40 |
||
|
平均 |
5.75 |
-0.75 |
5 |
5 |
||
第1アイテム内のカテゴリ平均:5.75、第2アイテム内のカテゴリ平均:-0.75
外的基準の平均:5 以上から、各アイテム内の平均値=0から、 基準化した予測値
Y’は、
Y’- 5= (7-5.75)・x11 + (4.5-5.75)・x12 -
(0+0.75)・x21 + (-1.5+0.75)・x22 となる。これから
Y’= 1.25・x11 - 1.25・x12 + 0.75・x21 - 0.75・x22 + 5 が基準化したときの線形予測式となる 基準化した線形予測式を求めるには、各係数からその

平均を引いて求めると
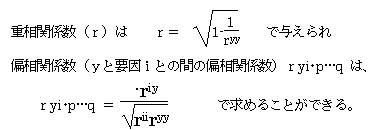
|
標本No |
アイテム1 |
アイテム2 |
実測値(y) 英語の点数 |
||
|
x11 |
x12 |
x21 |
x22 |
||
|
1 2 3 4 5 6 7 8 |
0 0 7 7 7 0 7 0 |
4.5 4.5 0 0 0 4.5 0 4.5 |
0 0 0 0 0 0 0 0 |
-1.5 0 0 -1.5 0 0 -1.5 -1.5 |
2 4 5 7 8 6 5 3 |
|
平均 |
5.75 |
-0.75 |
5 |
||

以上から、この線形予測式により、実測値の約60%が説明されており、アイテム1と実測値との偏相関係数=0.729、アイテム2と実測値との偏相関係数=0.539でアイテム1の方が実測値に与える影響は大きいので、より重要な要因である。
〈4〉線形予測式の評価について
求めた線形予測式が、もとのデータをどれくらい正確に予測しているのか、その精度を評価する。
①決定係数(R2)をみる。
決定係数R2は、重相関係数(r)の2乗に一致しており、0≦R2≦1の値を示す。
R2が1に近いほど、実測値yiと予測値Yiの相関が高く、よい予測値であるといえる。
②範囲(レンジ)を調べる。
各アイテム内の各カテゴリに与えた基準化された数量の範囲(数量の最大値-数量の最小値)をレンジという。レンジの大きいほど外的基準に与える影響が大きいので、より重要なカテゴリである。アイテム1=1.25-(-1.25)=2.5 アイテム2=0.75-(-0.75)=1.5 アイテム1の方がレンジ(範囲)が大きいので、アイテム1の方が外的基準に与える影響は大きい。
③偏相関係数を調べる。
各アイテムと外的基準との偏相関係数riyを調べ、riyの値が大きいほど外的基準に与える影響が大きいので、より重要なアイテムである。
ry1.2=0.729
ry2.1=0.539 であるから、アイテム1の方が外的基準に与える影響は大きい。