11.�@�P���z�u���U����
3�Q�ȏ�̕ꕽ�ς̍��̌�����s���ɂ́A2�Q�̕ꕽ�ς̍��̌�������̑g�ݍ��킹�̉��J��Ԃ����s���Ȃ���Ȃ�Ȃ��B���̂悤�Ȏ���1��Ō��肷����̂Ɂu�P���z�u���U���́v������B����f�[�^�ɂ����^����v����1�l������̂��u�P���z�u���U���́v�ł���A2�l������̂��u�Q���z�u���U���́v�ł���B�������A�e�f�[�^�͂قڐ��K���z�ɏ]���������U�ł�����̂Ƃ���B
11.1�@�P���z�u���U����
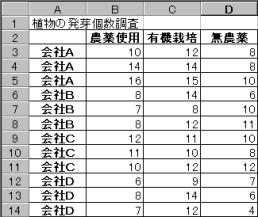
����G�߂̈�̐����3�n��Œ��ׂ��B��̐����͒n��ɂ�荷�����邩�L�א���5%�Ō�����s���B�ϓ��v���͒n��ɂ��Ⴂ�ł���A3�Q�̕ꕽ�ς̍������肷��̂ŁA�P���z�u���U���͂����s����B
�P���z�u���U���͂́A���U�����ԕϓ��i���q�ԕϓ�:�n��ɂ��ϓ��j�Ƌ����ϓ��i���q���ϓ�:����n����ł̕ϓ��j�Ƃɕ����ĕ��U������߁A���ԕϓ��������ϓ������傫�������肵�A���ԕϓ��������ϓ������傫����A�ꕽ�ςɍ�������Ƃ��錟��ł���B�������A�ǂ̌Q�Ԃō������邩�͕s���ł���B�ǂ̌Q�Ԃŕꕽ�ςɍ������邩�́A�{���E�t�F���[�j�̕��@��V�F�b�t�F�̕��@�Ȃǂ�����B
11.2�@1���z�u���U���͂̎��{
�i1�j�W�{�f�[�^����͂��A�c�[�����g�p���A�P���z�u���U���͂����s
�W�{�f�[�^�ŏW�߂��Ȃ������f�[�^�͂��̂܂܋ɂ��Ă����B
�c�[�������̓c�[�������U����:1���z�u���U���͂�I��
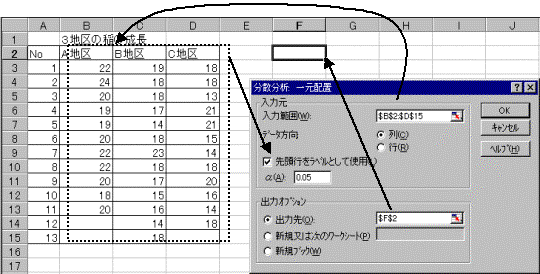
���͔͈͂́A���ڍs�iA�n��EB�n��EC�n��̕����̍s�j���܂߂Ĉ�x�̃h���b�O���ĕ��͂���f�[�^�͈͂��w�肷��B�擪�̕�����̍s�̓��x���Ƃ��Ďg�p����̂ŁA�u�擪�s�����x���Ƃ��Ďg�p�v�̗����N���b�N���ă`�F�b�N����B�o�͐���w�肵�AOK�{�^�����N���b�N����Ƃ��ׂɁu�P���z�u���U���͕\�v���v�Z����\�������B
�i2�j�쐬���ꂽ�u1���z�u���U���͕\�v����������B
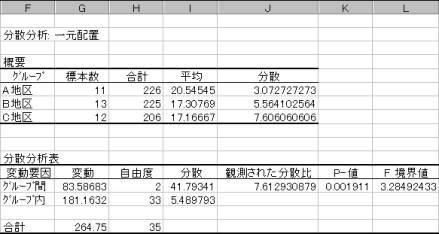

�@���ԕϓ��̕����aSA�́A�e�O���[�v�̕��ς��S���ς���ǂꂭ�炢����Ă��邩�ł���B�e�����i�O���[�v�j�ł̕��ςƑS�W�{�̕��ςƂ̍��̕����a�Ɋe�����ł̕W�{���������ċ��߂�B![]() �@�@�܂����ԕϓ��̎��R�x�́A������(�O���[�v��)-1�ł���B
�@�@�܂����ԕϓ��̎��R�x�́A������(�O���[�v��)-1�ł���B
�A�����ϓ��̕����aSE�́A�e�����̃f�[�^���e�����̕��ς���ǂꂭ�炢����Ă��邩�ł���B�e�����i�O���[�v�j�ł̕��ςƊe�f�[�^�Ƃ̍��̕����a���e�����ŋ��߁A����ɑS�����ō��v�������̂ł���B![]()
�@�܂������ϓ��̎��R�x�́A�S�W�{��-�������ł���B
�B�S�ϓ��̕����aST�́A���ԕϓ�SA��SE�����ϓ������������̂ł���B�܂��S�ϓ��̎��R�x�́A���ԕϓ��̎��R�x+�����ϓ��̎��R�x�ł���B
���蓝�v�ʂ͕��U��(F): ![]() �ł���A���R�xfA,fE��F���z�ɏ]���B
�ł���A���R�xfA,fE��F���z�ɏ]���B
(3)��������{
�@����������
�A�������@H0:���ԕϓ��͌��ʂ��Ȃ��iVA��VE)
�Η������@H1:���ԕϓ��͌��ʂ�����iVA��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@���蓝�v��(F): ![]() =7.612930879�@�͎��R�x2,33��F2,33���z�ɏ]��
=7.612930879�@�͎��R�x2,33��F2,33���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{(VA��VE�̌���ł��邩��E�Б���������{)
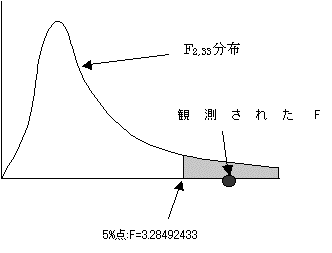
F2,33���z��5%�_��3.28492433�ł���B�ϑ����ꂽF�l��7.612930879�ł���A���̒l��5%�_F�l�����傫���B�܂��̎��̊m��:0.001911�ł��肱�̒l��0.05��菬�����B���ꂩ��A�����������p����B���ԕϓ��͌��ʂ�����Ƃ�����B3�Q�̕ꕽ�ςɍ�������Ƃ�����B��̐����͒n��ɂ�荷������Ƃ�����B�������ǂ̒n��Ԃŕꕽ�ςɍ������邩�s���ł���B
12.�@�J��Ԃ��̂Ȃ�2���z�u���U����
3�Q�ȏ�̕ꕽ�ς̍��̌�������{���鎞�A���̃f�[�^���قڐ��K���z�ɏ]���������^����v����2��(���ԕϓ���2��)���鎞���l����B�������A���q�̑g�ݍ��킹�ɂ�����ɉ��炩�̌��ʂ�^������ݍ�p(���݂��ɉe����^�����p)���Ȃ��Ƃ���B���̌��ݍ�p���F�߂��鎞�ɂ́A�J��Ԃ��̂���2���z�u���U���͂����{����B
12.1�@�J��Ԃ��̂Ȃ�2���z�u���U����
�j���ʂ�7�̋ƊE�ʂɏ��C���������Ƃ���A���̂悤�Ȍ��ʂ��B���̃f�[�^���珉�C���̋��^�͋ƊE�Ԃō��ق����邩�A�܂��j���Ԃō��ق����邩�A�L�m��5%�Ō�������{����B���C���ɂ����^����v����2����B1�͋ƊE�Ԃ̈Ⴂ�ł���A����1�͒j���Ԃ̈Ⴂ�ł���B�J��Ԃ��̂Ȃ�2���z�u���U���͂́A1���z�u���U���͂Ɠ��l�ɁA�S���U�����ԕϓ��Ƌ����ϓ��Ƃɕ����A���ԕϓ��������ϓ����傫�����ǂ���������s���B
12.2�@�J��Ԃ��̂Ȃ�2���z�u���U���͂̎��{
(1)�f�[�^����͂���B
(2)�c�[�����g�p���A�J��Ԃ��̂Ȃ�2���z�u���U���͂����{
�c�[�������̓c�[�������U����:�J��Ԃ��̂Ȃ�2���z�u��I��
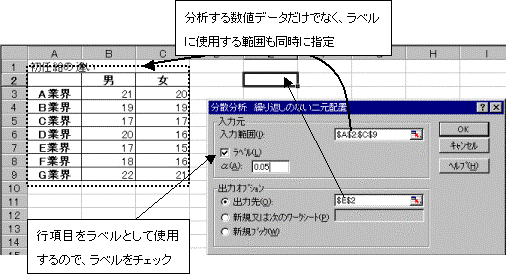
���͂Ɏg�p����f�[�^��͈͎w�肵�AOK�{�^�����N���b�N����ƕ��͌��ʂ��\�������B
(3)���͌��ʂ�����
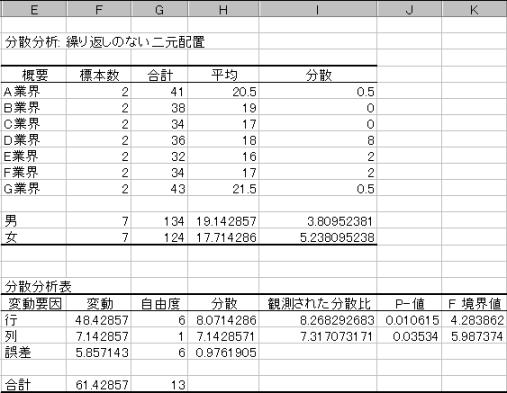

�@�S�ϓ�(T)�̕����a��(ST)�A�S�f�[�^���S���ς���ǂꂭ�炢����Ă��邩�ł���B
![]() �ƌX�̃f�[�^(Xij)���̕����a�ŋ��߂�B
�ƌX�̃f�[�^(Xij)���̕����a�ŋ��߂�B![]()
�A���ԕϓ�(A)�̕����aSA�́A�e����(�ƊE)�ł̕��ς��S���ς���ǂꂭ�炢����Ă��邩�ł���B�e�����i�ƊE�j�ł̕��ςƑS�W�{�̕��ςƂ̍��̕����a�Ɋe�����ł̕W�{�������������߂�B![]()
�܂����ԕϓ�(SA)�̎��R�x�́A������(�ƊE��)-1�ł���B
�B���ԕϓ�(B)�̕����aSB�́A�e����(�j��)�ł̕��ς��S���ς���ǂꂭ�炢����Ă��邩�ł���B�e�����i�j���j�ł̕��ςƑS�W�{�̕��ςƂ̍��̕����a�Ɋe�����ł̕W�{�������������߂�B![]()
�܂����ԕϓ�(SB)�̎��R�x�́A������(�j����)-1�ł���B
�C�����ϓ��̕����aSE�́ASE=ST-SA-SB���狁�߂�B
(3)��������{
(3-1)���ԕϓ�A(�ƊE�Ԃ̍���)�͌��ʂ����邩���肷��
�@����������
�A�������@H0:���ԕϓ�A�͌��ʂ��Ȃ��iVA��VE)
�Η������@H1:���ԕϓ�A�͌��ʂ�����iVA��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@���蓝�v��(F):FA�@=�@![]() �@=�@8.268292683�@�͎��R�xfA,fE(6,6)��F���z�ɏ]��
�@=�@8.268292683�@�͎��R�xfA,fE(6,6)��F���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{
�ϑ����ꂽF�l:8.268�́AF6,6(0.05):4.2838�����傫���B�܂����̎��̊m��:0.00106��0.05�����������A����Ċ��p��ɓ���B�A�����������p����B���ԕϓ�A�͌��ʂ�����Ƃ�����B�ƊE�Ԃŏ��C���ɈႢ������Ƃ�����B
(3-2)���ԕϓ�B(�j���Ԃ̍���)�͌��ʂ����邩���肷��
�@����������
�A�������@H0:���ԕϓ�B�͌��ʂ��Ȃ��iVB��VE)
�Η������@H1:���ԕϓ�B�͌��ʂ�����iVB��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@![]() �͎��R�xfB,fE(1,6)��F���z�ɏ]��
�͎��R�xfB,fE(1,6)��F���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{
�ϑ����ꂽF�l:7.31707�́AF1,6(0.05):5.98737�����傫���B�܂����̎��̊m��:0.003534��0.05�����������A����Ċ��p��ɓ���B�A�����������p����B���ԕϓ�B�͌��ʂ�����Ƃ�����B�j���Ԃŏ��C���ɈႢ������Ƃ�����B
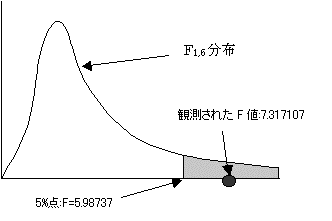
12.3�@���ݍ�p�̌���
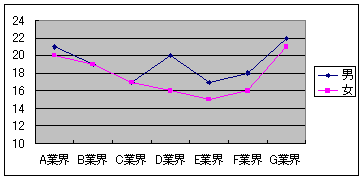
�J��Ԃ��̂Ȃ�2���z�u���U���͂ł́A���ݍ�p�̗L���͊m�F�ł��Ȃ��B���ݍ�p�̗L���ɂ��ẮA�J��Ԃ��̂���2���z�u���U���͂����{����K�v������B�J��Ԃ��̂Ȃ�2���z�u���U���͂����{���āA���ݍ�p���F�߂��邩�ǂ����́A�O���t��`���Ă݂�Ɖ\���̗L����������B�O���t�̉����ɐ���A�i�O���[�vA:�ƊE�j���Ƃ�A�c���ɏ��C���̒l���Ƃ�A�����a�i�j���j�̋��^����O���t�ɍ쐬����B���̎��O���t��������������������肵�Ă��鎞�ɂ́A���ݍ�p������\��������B
�O���t��`���ƁA2�̒����͌������Ȃ����������Ă��Ȃ��̂ŁA���ݍ�p�͂Ȃ����̂Ǝv����B
13.�@�J�Ԃ��̂���2���z�u���U����
����f�[�^�ɂ����^����v����2�l����B����2�̗v���ɂ��Ă������̐���(�O���[�v)�ɕ���������f�[�^�𑪒肷��B2�̗v���ɂ��Ă��ꂼ����ʂ����邩�A�܂�2�̈��q�ԂɌ��ݍ�p�����邩�����肷��B
13.1�@�J�Ԃ��̂���2���z�u���U����
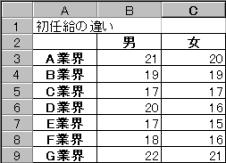
4�Ђ̐A���̎�q�̔����_��g�p�E�L�@�͔|�E���_���3��ނɕ�����3�ϑ������B�A���̔���ɂ��āA����A(�O���[�vA�F��Ђ̈Ⴂ)�Ɛ���B�i�O���[�vB:�͔|���@�̈Ⴂ�j�ɂ��A����ɈႢ�����邩�܂����q�Ԃ̌��ݍ�p�͂��邩���A�L�m��5%�Ō�����s���B
(1)�f�[�^�����
�f�[�^�͐���A(��Е�)���c�����ɁA����B(�͔|���@�̈Ⴂ)�������ɂƂ�A�A������3�̃f�[�^����͂��Ă����B
(2)�c�[�����g�p���A�J��Ԃ��̂���2���z�u���U���͂����{
�c�[�������̓c�[�������U����:�J��Ԃ��̂���2���z�u��I��
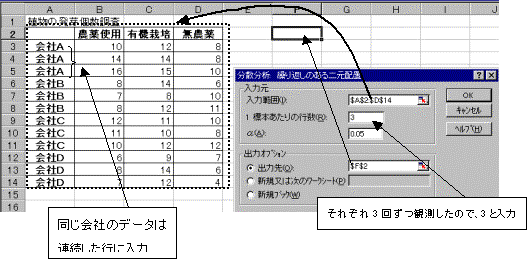
���͂Ɏg�p����f�[�^��͈͎w�肵�AOK�{�^�����N���b�N����Ƃ����ɕ��͌��ʂ��\�������B
(3)���͌��ʂ�����
���̂悤�ȕ��ƋC���ʂ��\�������B
|
���U����: �J��Ԃ��̂���z�u |
|
|
|
|
|||||||
|
�T�v |
�_��g�p |
�L�@�͔| |
���_�� |
���v |
|
|
|||||
|
��Ђ` |
|
|
|
|
|
|
|||||
|
�W�{�� |
3 |
3 |
3 |
9 |
|
|
|||||
|
���v |
40 |
41 |
26 |
107 |
|
|
|||||
|
���� |
13.33333 |
13.66667 |
8.666667 |
11.88888889 |
|
|
|||||
|
���U |
9.333333 |
2.333333 |
1.333333 |
9.111111111 |
|
|
|||||
|
��Ђa |
|
|
|
|
|
|
|||||
|
�W�{�� |
3 |
3 |
3 |
9 |
|
|
|||||
|
���v |
23 |
34 |
27 |
84 |
|
|
|||||
|
���� |
7.666667 |
11.33333 |
9 |
9.333333333 |
|
|
|||||
|
���U |
0.333333 |
9.333333 |
7 |
6.75 |
|
|
|||||
|
��Ђb |
|
|
|
|
|
|
|||||
|
�W�{�� |
3 |
3 |
3 |
9 |
|
|
|||||
|
���v |
33 |
33 |
30 |
96 |
|
|
|||||
|
���� |
11 |
11 |
10 |
10.66666667 |
|
|
|||||
|
���U |
1 |
1 |
4 |
1.75 |
|
|
|||||
|
��Ђc |
|
|
|
|
|
|
|||||
|
�W�{�� |
3 |
3 |
3 |
9 |
|
|
|||||
|
���v |
21 |
35 |
17 |
73 |
|
|
|||||
|
���� |
7 |
11.66667 |
5.666667 |
8.111111111 |
|
|
|||||
|
���U |
1 |
6.333333 |
2.333333 |
9.861111111 |
|
|
|||||
|
���v |
|
|
|
|
|
|
|||||
|
�W�{�� |
12 |
12 |
12 |
|
|
|
|||||
|
���v |
117 |
143 |
100 |
|
|
|
|||||
|
���� |
9.75 |
11.91667 |
8.333333 |
|
|
|
|||||
|
���U |
9.295455 |
4.628788 |
5.515152 |
|
|
|
|||||
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|||||
|
���U���͕\ |
|
|
|
|
|
|
|||||
|
�ϓ��v�� |
�ϓ� |
���R�x |
���U |
�ϑ����ꂽ���U�� |
P-�l |
F ���E�l |
|
||||
|
�W�{ |
72.22222 |
3 |
24.07407 |
6.37254902 |
0.002483 |
3.008786 |
|
||||
|
�� |
78.16667 |
2 |
39.08333 |
10.34558824 |
0.000575 |
3.402832 |
|
||||
|
���ݍ�p |
50.94444 |
6 |
8.490741 |
2.24754902 |
0.073123 |
2.508187 |
|
||||
|
�J��Ԃ��덷 |
90.66667 |
24 |
3.777778 |
|
|
|
|||||
|
|
|
|
|
|
|
|
|||||
|
���v |
292 |
35 |
|
|
|
|
|||||
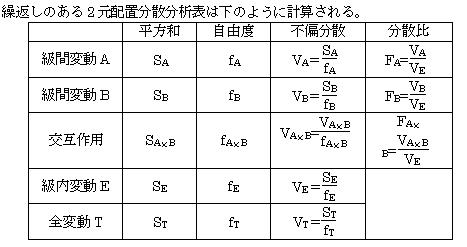
�ŏ��Ɋe�������Ƃ̕W�{������v����ϥ���U���v�Z����ĕ\������A�����ĕ��U���͕\���\�������B���U���͕\���݂Č�������{����B
(4)��������{
(4-1)���ԕϓ�A(��ЊԂ̍���)�͌��ʂ����邩���肷��
�@����������
�A�������@H0:���ԕϓ�A�͌��ʂ��Ȃ��iVA��VE)
�Η������@H1:���ԕϓ�A�͌��ʂ�����iVA��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@![]() �@�͎��R�xfA,fE(3,24)��F���z�ɏ]��
�@�͎��R�xfA,fE(3,24)��F���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{
�ϑ����ꂽF�l:6.37254902�́AF3,24(0.05):3.008786�����傫���B�܂����̎��̊m��:0.002483��0.05�����������A����Ċ��p��ɓ���B�A�����������p����B���ԕϓ�A�͌��ʂ�����Ƃ�����B��ЊԂŐA���̎�q�̔���ɈႢ������Ƃ�����B
(4-2)���ԕϓ�B(�͔|���@�̈Ⴂ)�͌��ʂ����邩���肷��
�@����������
�A�������@H0:���ԕϓ�B�͌��ʂ��Ȃ��iVB��VE)
�Η������@H1:���ԕϓ�B�͌��ʂ�����iVB��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@![]() �@�͎��R�xfB,fE(2,24)��F���z�ɏ]��
�@�͎��R�xfB,fE(2,24)��F���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{
�ϑ����ꂽF�l:10.34558824�́AF2,24(0.05):3.402832�����傫���B�܂����̎��̊m��:0.000575��0.05�����������A����Ċ��p��ɓ���B�A�����������p����B���ԕϓ�B�͌��ʂ�����Ƃ�����B�͔|���@�̈Ⴂ�ɂ��A���̎�q�̔���ɈႢ������Ƃ�����B
(4-2)���ݍ�p�͌��ʂ����邩���肷��
�@����������
�A�������@H0:���ݍ�p�͌��ʂ��Ȃ��iVA�~B��VE)
�Η������@H1:���ݍ�p�͌��ʂ�����iVA�~B��VE�j
�A���蓝�v�ʁiF�j�����߂�
�@![]() �@�͎��R�xfA�~B,fE(6,24)��F���z�ɏ]��
�@�͎��R�xfA�~B,fE(6,24)��F���z�ɏ]��
�B�L�m��5%�ŏ�Б���������{
�ϑ����ꂽF�l:2.24754902�́AF6,24(0.05):2.508187�����������B�܂����̎��̊m��:0.073123��0.05�����傫���A����Ċ��p��ɓ���Ȃ��B�A�����������p���鎖�͂ł��Ȃ��B���ݍ�p�����ʂ��Ȃ������p�ł��Ȃ��B
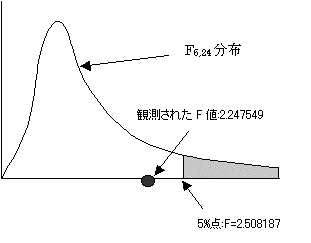
�ȏォ���q�̔���́A��ЊԂō��ق�����܂��͔|���@�ł����ق��F�߂���B�������A����1(��ЊԂ̈Ⴂ)�Ɛ���2(�͔|���@�̈Ⴂ)�Ƃ���2�̈��q�Ԃ̌��ݍ�p�͌��ʂ��Ȃ��Ƃ��������͊��p�ł��Ȃ��B
(5)�v�[�����O
�@���ݍ�p�Ɍ��ʂ��Ȃ��Ɣ����������ɂ́A���ݍ�p�̕ϓ��������ϓ��Ƀv�[���i�ꏏ�ɂ���j���čēx2���z�u���U���͂����{����̂��]�܂����B
�v�[��������̋����ϓ�E'�̕����a��SE'�܂����R�x��fE'�Ƃ����
�����a��SE'=SE+SA�~B�@���R�x��fE'=fE+fA�~B�ƂȂ�B![]()
����ɂ��v�[�����O��̐���A�̕��U��(FA')�́A![]()
�v�[�����O��̐���B�̕��U��(FB')�́A![]()
�ȏォ��v�[�����O�������2���z�u���U���͕\���쐬�����
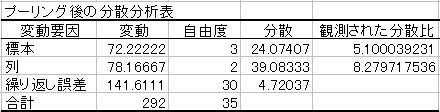
�v�[�����O������̕��U���p���čēx��������{
�v�[�����O��̐���A�̕��U��:�@�@���R�x��3��30
�v�[�����O��̐���B�̕��U��:8.279717�@���R�x��2��30
���ꂩ��F���z�Ɋւ�������g�p���Ċm�������߂�B
����A�FF3,30=5.10039�@��0.005693�@�@����B�FF2,30=8.279717�@��0.005693
���̒l�͂������0.05��菬�����B����Ċ��p��ɓ���B�v�[��������p��ɓ���̂ŁA����A�E����B�Ƃ��Ɍ��ʂ�����Ƃ�����B

14.�@2�ϗʊԂɊւ��镪��
14.1�@2�ϗʊԂ̑���
2�ϗʁiX�Y)�Ԃɉ��炩�̊W�����邩�ׂ�B�ϗ�X�Ƃ���Ɉˑ�����ϗ�Y������A����X�EY�̃y�A�ɂȂ��Ă���f�[�^��n���鎞�A����2�ϗ�X�EY�Ԃ̊W���ǂꂭ�炢���邩�ׂ�B���ܐl�Ԃ̐g���Ƒ̏d�̃f�[�^�Ԃɉ��炩�̊W�����邩�ׂ�B�g�����̏d�����K���z�ɏ]���f�[�^�ł���B2�ϗʊԂʼn��炩�̊W�����邩�ׂ�ɂ́A�u�U�z�}���쐬����v���u���W�������߂�v�̏��ԂɎ��s���A���֊W�ׂ�B
14.1.1�@�U�z�}�̍쐬
2�ϗʂ̊W�����o�I�ɕ\�����A�ǂ̂悤�ȊW�����邩�ׂ�B
10�l�̊w��������Ɛ��w�̎��������B���̌��ʂ����̂悤�ɂȂ������A����̓_���Ɛ��w�̓_���Ԃɉ��炩�̊W�����邩�ׂ�B
�����ɍ���̓_���A�c���ɐ��w�̓_�����Ƃ�A10�l�̊w���̓_�����Y������ʒu�Ƀv���b�g���Ă����B(�U�z�}���쐬����)
�@EXCEL�ɂ̓O���t�쐬�@�\������̂ŁA����𗘗p���ĎU�z�}���쐬����B

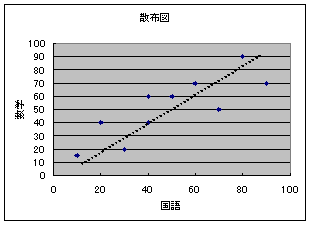 �쐬���ꂽ�U�z�}
�쐬���ꂽ�U�z�}
�쐬���ꂽ�U�z�}������ƁA�E�オ��̒�����Ƀf�[�^������ł���X��������B����̓_���������Ȃ�A���w�̓_���������Ȃ�X���ɂȂ��Ă���B���̂悤�Ȏ��A���̑��ւ�����Ƃ����B�܂����̋t�ɉE������̒����̌X�������鎞�ɂ́A���̑��ւ�����Ƃ����B�f�[�^�����炩�̒�����̌X���������Ȃ����́A���ւ��Ȃ��Ƃ����B
�U�z�}���쐬�����A���̂悤�ȌX��������ꂽ���A���ꂼ�ꐳ�̑��ցE���֖����E���̑��ւƂ����B
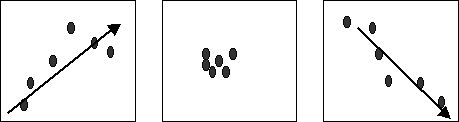
�u���̑���:�E�オ��̌X���v�u���֖���:�����X���Ȃ��v�u���̑���:�E������̌X���v
14.1.2�@���W��
�U�z�}���쐬�������ʁA�E�オ��E�E������̂悤�ȌX��������ꂽ���ɂ́A2�ϗʊԂɉ��炩�̑��ւ����肻���Ȃ̂ŁA�ǂꂭ�炢�̑��ւ����邩���u���W���v�����߂āB���̓x�������m�F����B
���W����r�Ƃ���ƁA���W����-1��r��+1�͈̔͂̒l���Ƃ�B
r��-1�ɋ߂��قǕ��̑��ւ������Br��+1�ɋ߂��قǐ��̑��ւ������B�܂�r��0�ɋ߂��قǑ��ւ��Ȃ��B
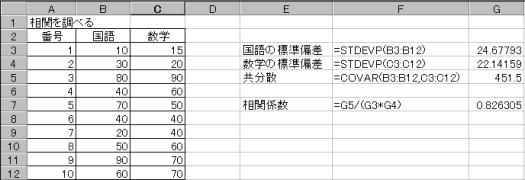
(1)�c�[�����g�p���đ��W�������߂�
�c�[�������̓c�[�������ւƑI�����A���W�������߂�Q�ϗʂ͈̔͂��w��
�Ō��OK�{�^�����N���b�N����ƁA���W���s�\�������B


����̃f�[�^�Ɛ��w�̃f�[�^�̑��W��:0.826305�Ƌ��߂�ꂽ�B���̒l��+1�ɋ߂��̂ŁA�������̑��ւ�����Ƃ�����B
(2)�����g�p���đ��W�������߂�B
���W�������߂���c��correl(�ϐ�1�͈�,�ϐ�2�͈�)

(3)�W�����E�����U��p���đ��W�������߂�B
�ϗ�X�̕�W�c�ɑ���W��������x�A�ϗ�Y�̕�W�c�ɑ���W��������y�A2�ϗ�(X,Y)�̋����U��Sxy�Ƃ��鎞�A���W��(r)�́A![]() �ŋ��߂���B
�ŋ��߂���B
��W�c�ɑ���W���������߂��: =stdevp(�ϐ��͈�)
2�ϗ�(X,Y)�̋����U�����߂��: =covar(�ϐ�1�͈�,�ϐ�2�͈�)
15. �P��A����
15.1�@�P��A�������߂�B
2�ϗʊԂɑ��ւ����鎞�A����2�ϗʊԂɐ��`��A�������l����B
���`��A������:Y=b1x+b0�Ƃ��āA���f�[�^�Ƃ��̒����Ƃ̎c�����ÂƂ���BY=b1x+b0�̒����́A���ׂĂ̕W�{�f�[�^�ɂ��āA���̎c�����ŏ��ɂȂ�悤�ɐݒ肷��K�v������B���̒�������e�W�{�f�[�^�Ƃ̂������v�邽�߂ɁA�e�c���̕����a���Ƃ�A���̎c�������a���ŏ��ɂȂ�悤�ɂ���B���̂悤�ȕ��@���ŏ�2��@�Ƃ����B�W�{�f�[�^�́A����:Y=b1x+b0����c��(��)����Ă���̂ŁAy=b1x+b0+�Âƕ\���B���ꂩ����`��A���f����yi=��1xi+��0
+��i�@(i=1,2,�cn)�Ƃ���B
�c��(��)�ɂ���
�@��i�ƃ�j�͂��݂��ɓƗ��ł���A���K���zN(0,��2)�ɏ]���B
�A��i�̊��Ғl(���ϒl)��0�ł���A�܂����U�͈��ł���B
�̉��艺�ŁA�P��A����Y=b1x+b0�Ƃ���ƁAb1,,b0�̓�1,��0�̐���ʂł���B
�c���ɒ��ڂ��A��i=yi-Yi�@����@��i=yi-b1�xi-b0�@���̎c�������ׂĂ̕W�{�ɂ��č��v���A���̍��v���ŏ��ɂ���悤��b1�b0�����߂�ƁA�P��A�������߂���B

��(��i)2=��(yi-b1�xi-b0)2�@�@f=��(yi-b1�xi-b0)2�@�Ƃ������A����f���ŏ��ɂ���b1�b0�����߁A�P��A�������߂�B
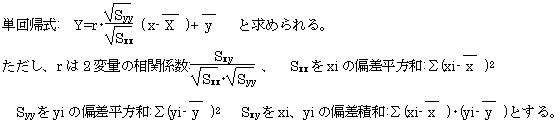
15.2�@�����ϗʂƖړI�ϗ�
�@����̓_����X�A���w�̓_����Y�Ƃ���B����̓_���Ɛ��w�̓_���Ԃɂ͐��̑��ւ�����A����̓_���������Ȃ�ƁA���w�̓_���������Ȃ�B���w�̓_��(Y)�͍���̓_��(X)�Ɉˑ����Ă���B���̂悤��2�ϗʊԂɒ����I�ȊW���F�߂���B���̒������v�Z���ċ��߂�ƒP��A�������߂���B���̒P��A���𗘗p����ƁA����̓_�����琔�w�̓_����\�����邱�Ƃ��ł���B���ܗ\�����ċ��߂�̂́u���w�v�̓_���ł���A���̗\���̌��ƂȂ�̂́u����v�̓_���ł���B���̂悤�ɋ��߂�ϗʂ��u�ړI�ϗʂ܂��͏]���ϗʁv�ƌĂсA���̗\���̂��ƂƂȂ�ϗʂ��u�����ϗʂ܂��͓Ɨ��ϗʁv�Ƃ����B�ړI�ϗʂ͏��1�ł���A�����ϗʂ�1�̎����u�P��A���́v�ƌĂсA�����ϗʂ�2�ȏ�̎����u�d��A���́v�Ƃ����B
15.3�@�P��A���͂����{
15.3.1�@���̓c�[�����g�p���P��A���͎��{
(1)���͂���f�[�^����͂��A�c�[�������̓c�[������A��I������B
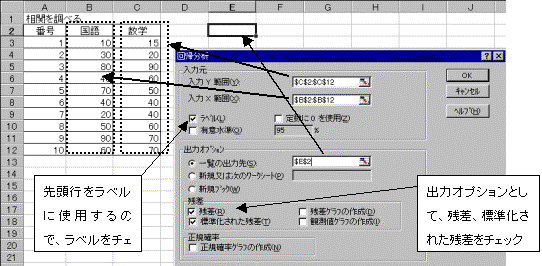
�@����Y�͈͂́A�ړI�ϗʂ͈̔͂��w�肷��B�擪�s�����x���Ƃ��Ďg�p���鎞�́A�����̓��������ڍs���͈͂ɓ����B
�A����X�͈͂́A�����ϗʂ͈̔͂��w�肷��B�擪�s�����x���Ƃ��Ďg�p���鎞�́A����Y�͈͂Ɠ��l�Ɏw�肷��B
�B���͔͈͂̐擪�s�����x���Ƃ��Ďg�p���鎞�́A���x���̗����N���b�N���ă`�F�b�N�B
�C�o�͐�́A���͌��ʂ�\������擪�̃Z���ʒu���w��B
�D�o�̓I�v�V�����Ƃ��āA�c���A�W�������ꂽ�c�����N���b�N���ă`�F�b�N�B
�ȏ�����Ă�OK�{�^�����N���b�N����Ƃ����ɕ��͌��ʂ��\�������B
(2)���͌��ʂׂ�
���̂悤�ȕ��͌��ʂ���B
|
�T�v |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
�d���� R |
0.826305 |
|
|
|
|
|
|
|
|
�d���� R2 |
0.68278 |
|
|
|
|
|
|
|
|
� R2 |
0.643127 |
|
|
|
|
|
|
|
|
�W���덷 |
13.94262 |
|
|
|
|
|
|
|
|
�ϑ��� |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
���U���͕\ |
|
|
|
|
|
|
|
|
|
|
���R�x |
�ϓ� |
���U |
�ϑ����ꂽ���U�� |
�L�� F |
|
|
|
|
��A |
1 |
3347.328 |
3347.328 |
17.21907 |
0.003211 |
|
|
|
|
�c�� |
8 |
1555.172 |
194.3966 |
|
|
|
|
|
|
���v |
9 |
4902.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
�W�� |
�W���덷 |
t |
P-�l |
���� 95% |
��� 95% |
���� 95.0% |
��� 95.0% |
|
�ؕ� |
15.17241 |
9.802094 |
1.547875 |
0.160242 |
-7.43127 |
37.7761 |
-7.43127 |
37.7761 |
|
���� |
0.741379 |
0.178663 |
4.149587 |
0.003211 |
0.32938 |
1.153378 |
0.32938 |
1.153378 |
|
|
|
|
|
|
|
|
|
|
|
�c���o�� |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
�ϑ��l |
�\���l: ���w |
�c�� |
�W���c�� |
|
|
|
|
|
|
1 |
22.58621 |
-7.58621 |
-0.57711 |
|
|
|
|
|
|
2 |
37.41379 |
-17.4138 |
-1.32472 |
|
|
|
|
|
|
3 |
74.48276 |
15.51724 |
1.180447 |
|
|
|
|
|
|
4 |
44.82759 |
15.17241 |
1.154215 |
|
|
|
|
|
|
5 |
67.06897 |
-17.069 |
-1.29849 |
|
|
|
|
|
|
6 |
44.82759 |
-4.82759 |
-0.36725 |
|
|
|
|
|
|
7 |
30 |
10 |
0.760733 |
|
|
|
|
|
|
8 |
52.24138 |
7.758621 |
0.590224 |
|
|
|
|
|
|
9 |
81.89655 |
-11.8966 |
-0.90501 |
|
|
|
|
|
|
10 |
59.65517 |
10.34483 |
0.786965 |
|
|
|
|
|

(2-1)��A�W���Ɋւ��镪�͌��ʂ�����
|
��A���v |
|
|
�d���� R |
0.826305 |
|
�d���� R2 |
0.68278 |
|
� R2 |
0.643127 |
|
�W���덷 |
13.94262 |
|
�ϑ��� |
10 |
�@�d����R
�d����R�Ƃ́A�d���W���ł���A�ړI�ϗ�Y(���ۂ̐��w�̓_��)�Ɖ�A����蓾��ꂽ�\���lY'(��A�����瓾��ꂽ���w�̗\���_��)��2�ϗʊԂ̑��W���̂��Ƃł���BR=0.826305�ł���A2�ϗʊԂ̑��ւ͂��Ȃ荂���Ƃ�����B�����ϗ�(����̓_��)�ƖړI�ϗ�(���w�̓_��)�Ԃ̑��W���ł͂Ȃ��A�ړI�ϗʂƗ\���l�ϗʂƂ̑��ւł���B
�A�d����R2
�����f�[�^�́A�P��A�����̂܂��ɂ���ĎU�݂��Ă���B���̂���̏������قǒP��A���̂��Ă͂܂肪�ǂ�(���x������)�����Ƃ�����B�܂������ϗ�(X)�̖ړI�ϗ�(Y)�ɗ^����e�����傫���Ƃ�����B�܂茈��͂��傫���Ƃ�����̂ŁAR2������W���Ƃ������B

��A����
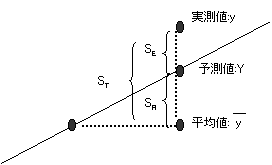
�B�R2
����W����d���W���́A�����ϗʂ̌��𑝂₵�Ă����ƒP���ɑ傫���Ȃ�X��������B�����ŁA�P���ɐ����ϗʂ̐��𑝂₵�Ă��A����W�����傫���Ȃ�Ȃ��悤�ɒ����������̂Ɏ��R�x�����ς���W��(�R2)������B

(2-2)��A���̐M����������
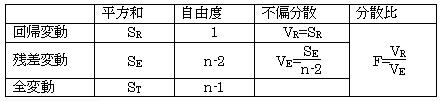
(2-2.1)�@���U���͕\���g�p������@
��A�����g�p���āA�����ϗʂ���ړI�ϗʂ̒l��\�����鎞�A���̗\���l���ǂꂭ�炢�M����������̂������肷����@�ɁA���U���͕\���g�p������@������B���U���͕\�ł́A�S�ϓ�(ST)����A���ϓ�(SR)�Ǝc���ɂ��ϓ�(SE)�Ƃɕ����A��A�ɂ��ϓ�(SR)���c���ɂ��ϓ�(SE)������������A��A�����ŋ��߂��\���l�́A�c���ɂ��e���̕����傫���̂ŗ\���ɂ͖𗧂��Ȃ��Ƃ�����@�ł���B�����l�̕ϓ�(ST)=��A�ɂ��ϓ�(SR)+�c���ɂ��ϓ�(SE)�B
�c�����������قǁA�����l�̕ϓ�(ST)����A�ɂ��ϓ�(SR)�ƂȂ�A�ǂ��\���l����B
�P��A�̎��̕��U���͕\�͉��̂悤�ɂȂ�B
![]() ���R�x1,n-2��F���z�ɏ]���BVR��VE�����傫�������肷��̂ŁA�E�Б���������{����B
���R�x1,n-2��F���z�ɏ]���BVR��VE�����傫�������肷��̂ŁA�E�Б���������{����B
|
���U���͕\ |
|
|
|
|
|
|
|
���R�x |
�ϓ� |
���U |
�ϑ����ꂽ���U�� |
�L�� F |
|
��A |
1 |
3347.328 |
3347.328 |
17.21907 |
0.003211 |
|
�c�� |
8 |
1555.172 |
194.3966 |
|
|
|
���v |
9 |
4902.5 |
|
|
|
�@����������
�A�������@H0:��A�����͗\���ɖ𗧂��Ȃ�((VR��VE)
�Η������@H1:��A�����͗\���ɖ𗧂�(VR>VE)
�A���蓝�v��(F)�ׂ�
![]()
�B�L�א���5%�ʼnE�Б���������{
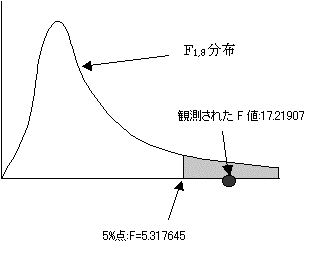
���R�x1,8�̏㑤0.05%�͊����g�p���āA=FINV(0.05,1,8)=5.317645�ƌv�Z�����B
�ϑ����ꂽF�l�́AF1,8(0.05)=5.317645�����傫���B�܂��̎��̊m��:0.003211�ł���A���̒l��0.05�����������B����Ċ��p��ɓ���B�A�����������p����B��A���͗\���ɖ𗧂Ƃ�����B
(2-2-2)�@����W�����g�p������@
����W���iR2)���g�p���āA��A���̌�������{����B����W��������ƁA�S�ϓ��ɑ����A�ϓ��̊�����������̂ŁA���̒l���傫���قlj�A���̐M�����͍����Ƃ�����B�S�ϓ��ɐ�߂��A�ϓ���R2%����Ƃ�����B

(2-3)�@�Ή�A�W����Y�ؕЂ̐M����������
��A�����͕̂��U���͂̌��ʐM����������Ɣ��������B�P��A���́AY=b1x+b0�ŕ\�����B���̎�b1��Ή�A�W���ƌĂсAb0��Y�ؕЂƂ����B���̕Ή�A�W����Y�ؕЂ��M���ł��邩������s���B
�@�W���덷(SE:Standard Error)
�W���덷(SE)�Ƃ́A����l�̕W����(SD)�������B
�����ϗ�(X)������l(y)��\���l(Y)��c��(��)��c������(��2)�̊W��\�ɂ���B

|
|
�W�� |
�W���덷 |
t |
P-�l |
���� 95% |
��� 95% |
���� 95.0% |
��� 95.0% |
|
�ؕ� |
15.17241 |
9.802094 |
1.547875 |
0.160242 |
-7.43127 |
37.7761 |
-7.43127 |
37.7761 |
|
���� |
0.741379 |
0.178663 |
4.149587 |
0.003211 |
0.32938 |
1.153378 |
0.32938 |
1.153378 |
�����ϗ�(����)�̕W���덷�́A��̌v�Z������0.178663�B�܂�Y�ؕЂ̕W���덷�F9.802094�ƌv�Z���ꋁ�߂��Ă���B
(2-3-1)�@�Ή�A�W��(b1)�̐M���������肷��B
�@����������
�A�������@�@H0:��1��0�@(�����ϗ�X�̕��A�W����0�ł���j
�Η������@�@H1:��1��0�@(�����ϗ�X�̕��A�W����0�ł͂Ȃ��j
�A���蓝�v��(T)�����߂�
![]()
�B�L�א���5%�ŗ�����������{
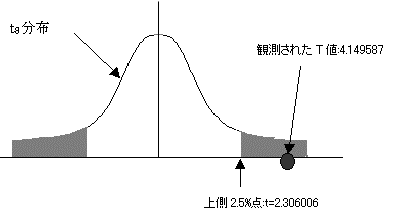
���R�x8��t���z�㑤0.025���_��=tinv(0.05,8)=2.306006�ł���B�ϑ����ꂽt�l:4.149587�͂��̒l�����傫���B�܂����̎��̊m��:0.003211�ł���0.05�����������B����Ċ��p��ɓ���B�A�����������p����B�Ή�A�W��(b1)�͗\���ɖ𗧂Ƃ�����B
(2-3-2)�@Y�ؕ�(B0)�̐M���������肷��B
�@����������
�A�������@�@H0:��0��0�@
�������@�@H1:��0��0�@
�A���蓝�v��(T)�����߂�

�B�L�א���5%�ŗ�����������{
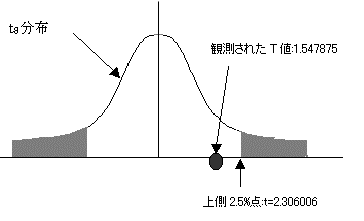
���R�x8��t���z�㑤0.025���_��=tinv(0.05,8)=2.306006�ł���B�ϑ����ꂽt�l:1.547875�͂��̒l�����������B�܂����̎��̊m��:0.160242�ł���0.05�����傫���B����Ċ��p��ɓ���Ȃ��B�A�����������p���邱�Ƃ͂ł��Ȃ��BY�ؕ�(b0)�͗\���ɖ𗧂��Ȃ��Ƃ����A�����������p�ł��Ȃ��B
�ȏォ��A��A�������̂͗\���ɖ𗧂Ƃ�����B�܂��Ή�A�W��(b1)�͗\���ɖ𗧂��AY�ؕ�(b0)�͗\���ɖ𗧂Ƃ͂����Ȃ��B
(2-4)�@��A�����g�p�����\���l
��A���͂ɂ�苁�߂�ꂽ�P��A�\�����́AY=0.741379x+15.17241�ł���B���̎���p���āA����̓_�����琔�w�̓_����\������B
x:����̓_���ł��邩��A�������̍���̒l�����Đ��w�̓_��Y���v�Z���ċ��߂�B�Ȃ��A���̓c�[���ł́A���̗\���l���v�Z����ĕ\������Ă���B
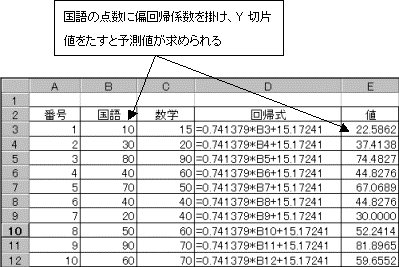
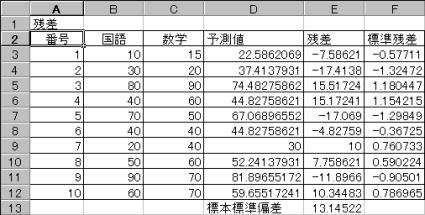
(2-5)�@�c���ׂ�
�c��(��)�́A�����l(y)�Ɨ\���l(Y)�̍��ł���B��i=yi-Yi
���̎c����W��������ƁA���̃f�[�^�̑傫����P�ʂ��C�ɂ����ɍςށB�W�������ꂽ�c���́A�W�{�Ɋ�Â��c���̕W���������߁A�e�c�������̕W�����Ŋ���B
![]() �@���̕W���c���̒l���}3.0���z���Ă���u�͂���l�v�̉\��������B
�@���̕W���c���̒l���}3.0���z���Ă���u�͂���l�v�̉\��������B
(2-6)�@�P��A�����g�p���āA���m�̒l��\������B
�����ϗ�(����)�̒l�͂킩���Ă��邪�A�ړI�ϗ�(���w)�̓_�����s���Ȏ��A���߂��P��A�����g�p���āA�l��\������B���̂悤�ɋ��߂��P��A�����g�p���Ė��m�̒l��\�����鎞�́A�g�p���������ϗʂ͈͓̔��ŗ\�����鎖���]�܂����B�g�p���������ϗʂ���傫���O�ꂽ�͈͂ŗ\������ƁA�덷���傫���Ȃ���p�ɓK���Ȃ��Ȃ�B
�����ϗʂł��鍑��̓_����10�ȏ�90�ȉ��ł���B�����ł��͈͓̔��ł̍���̓_�����g�p�悤�ɂ���B���܍���̎������������̂�3�������Ƃ���B���̓_���́A25�A68�A72�A80�_�ł������B����4���̐��w�̓_���͉��_�Ɨ\�z����邩�B�P��A�����g�p���ė\������B
���߂��P��A��:Y=0.741379x+15.17241�@x�̕����͍���̓_���ł��邩��A�����ɍ���̓_��������ď����l���v�Z����B
���̕\�̂悤�ɗ\���l�邱�Ƃ��ł���B
|
|
���� |
���͂����� |
�v�Z���� |
|
11 |
25 |
=0.74137931*B15+15.17241379 |
33.7068966 |
|
12 |
68 |
=0.74137931*B16+15.17241379 |
65.5862069 |
|
13 |
72 |
=0.74137931*B17+15.17241379 |
68.5517241 |
|
14 |
80 |
=0.74137931*B18+15.17241379 |
74.4827586 |
15.3.3�@��A�Ɋւ����
���̓c�[�����g�p���Ȃ��Ă��A��A�Ɋւ�������g�p����Ή�A�����Ɨ\���l�����߂邱�Ƃ��ł���B
(1)�P��A�����Ɋւ����
�@�P��A�����̌X�������߂��(�ϗ�X�̌W�����j
�@�@�@=slope(�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�)
�A�P��A������Y�ؕЂ����߂��
�@�@�@=intercept(�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�)
�B��x�ɒP��A�����̌X����Y�ؕЂ����߂��
�@�@�@=linest(�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�,[�萔],[�])
�萔�͎w�肵�Ȃ��Ă��悢�B���true,false�̂����ꂩ���w��A�ȗ������false�Ƃ݂Ȃ����Btrue���w�肷��ƁA��A�Ɋւ��镪�͏�\������邽����linest���ł́A�z�����쐬���Ȃ���Ε\������Ȃ��B�B
(2)���W���Ɋւ����
�@2�ϗʊԂ̑��W�������߂��
�@�@�@=correl(�ϗ�1�͈�,�ϗ�2�͈�)
�A����W���iR2)�����߂��
�@�@�@=rsq(�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�)
(3)�P��A�����g�p���ė\���l�����߂��
�@�\���l�����߂��
�@�@�@=trend(�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�,�萔)
�@�@�@=forecast(�萔,�ړI�ϗʂ͈̔�,�����ϗʂ͈̔�)
(2)�����g�p���āA�P��A�������߂�B
�P��A���́AY=b1x+b0
�ړI�ϗ�(���w�̓_��)�͈̔�:C3:C12�A�����ϗ�(����̓_��)�͈�:B3:B12�ł���B
�X��:=slope(�ړI�ϗʔ͈�,�����ϗʔ͈�)����0.74137931�Ƌ��߂���B
Y�ؕ�:=intercept(�ړI�ϗʔ͈�,�����ϗʔ͈�)����15.1724438�Ƌ��߂���B
����āA�P��A���́AY=0.74137931X+15.1724438�Ƌ��߂���B
�d���W��:=rsq(�ړI�ϗʔ͈�,�����ϗʔ͈�)���0.68277972
���W����2�ϗ�X�Y�̑��ւł��邩��=correl(�ϗ�1�͈�,�ϗ�2�͈�)���0.82630486

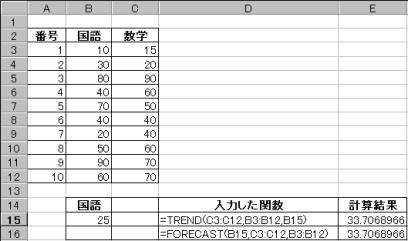
(3)�����ϗ�(����̓_��)��25�_�̎��̖ړI�ϗ�(���w�̓_��)�����ŋ��߂�B
����̓_��)(25)�Z��:B15�@
=trend(�ړI�ϗʔ͈�,�����ϗʔ͈�,����̓_��)��萔�w�̓_����33.7068966�_�Ɨ\��
=forecast(����̓_��,�ړI�ϗʔ͈�,�����ϗʔ͈�)��萔�w�̓_����33.7068966�_�Ɨ\��
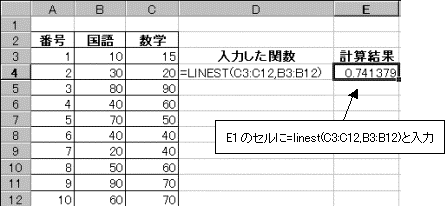
(3)�P��A�����̌X����Y�ؕЂ���x�̋��߂���̎g�p
�v�Z���ʂƂ��āA�u�X���v�ƁuY�ؕЁv��2�̒l���~�����B���̑��̕��͌��ʂ��\��������B
�@=linest(�ړI�ϗʔ͈�,�����ϗʔ͈�,,true)�ł܂������̌X�������߂�B
�@�@�@��true���ȗ�����ƁA�e�ϗʂ̌W����Y�ؕВl�����̕\���ƂȂ�B
�A�z�����쐬����B
���߂����ϐ���2�A����1�߂̌X�������߂��Ă���̂ŁA����1��z���ŕ\��������B
������͂����ʒu����E����1�Z�����h���b�O���A�X�ɉ�������5�s���͈͎w�肷��(���߂������l��2����)�������o�[���N���b�N���ăA�N�e�B�u�ɂ��遨CTRL�L�[+SHIFT�L�[+ENTER�L�[�������ƁA2�Ԗڂɐ��l:Y�ؕЂ₻�̑��̕��͌��ʂ��\�������B
![]()
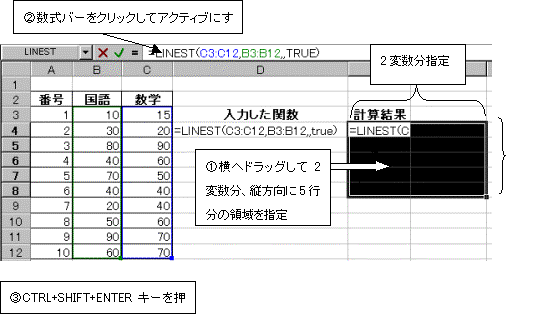
�Blinest���̌v�Z���ʂ��m�F
linest�����g�p���A�z���ɂ���Ɖ��̂悤�Ȍv�Z���ʂ��\�������B
|
|
Y�ؕ� |
|
X1�̕W���덷 |
Y�ؕЂ̕W���덷 |
|
����W�� |
�W���덷 |
|
���U�� |
���R�x |
|
��A�̕����a |
�c���̕����a |
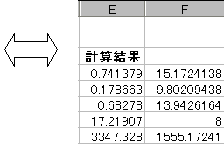
���ꂩ��A�X��:0.741379�@Y�ؕ�:15.1724138�@
����ĒP��A��:Y=0.741379X+15.1724438�Ƌ��߂���B
�܂����̒P��A���̐M�����͕��U��(F):17.21907�@���R�x1�A8��F���z�ׂ�悢�B�i�P��A�ł�1�Ԗڂ̎��R�x��1)
��A�̕����a��3347.328�@���R�x:1�@�c���̕����a:1555.17241�@���R�x:8
VR=3347.328�@VE=1555.17241��8=194.39655�@![]() �@�Ƌ��߂���B
�@�Ƌ��߂���B
=finv(0.05,1,8)=5.317645���玩�R�x1,8�̏㑤0.05�m����F�l���r����悢�B
���蓝�v��(F)=17.219��F1,8(0.05)=5.317645�@�ł��邩��@VR��VE�Ƃ����A�����������p�ł���B
16.�@�d��A����
�P��A���͂ł́A�ړI�ϗʂ�1�����ϗʂ�1�ł������B�ړI�ϗʂ͏��1��(�\������l��1��)�ł��邪�A�����ϗʂ�2�ȏ�̎����d��A���͂Ƃ����B�P��A�ɔ�א��x�͏オ�邪�A������ł́A���ʂȕϗʂ��g���Ă��Ȃ������肷��K�v������A���ʂȕϗʂ��g�킸(�ϗʑI��@)�ŗǂ̏d��A����K�v������B
16.1�@�d��A�������߂�
��ʂɐ����ϗʂ�p���鎞�̏d��A���f���́@yi=��1�x1i+��2�x2i+�c+��p�xpi+��0+��i�@(i=1,2�A�@�cn)�ŕ\�����B���̎��P��A���l��
�c��(��)�ɂ���
�@��i�ƃ�j�͂��݂��ɓƗ��ł���A���K���zN(0,��2)�ɏ]���B
�A��i�̊��Ғl(���ϒl)��0�ł���A�܂����U�͈��ł���B
�̉��艺�ŁA�d��A����Yi=b1�x1i+b2�x2i+�c+bp�xpi+b0�Ƃ���ƁAb0,,b1�cbp�̓�0,��1�c��p�̐���ʂł���B
b0,,b1�cbp��Ή�A�W���ƌĂсA��0,��1�c��p���Ή�A�W���Ƃ����B�P��A���Ɠ��l�Ɏc�������a��(��i)2���ŏ��ɂ���悤�ȁAb0,,b1�cbp�����߂�悢�B

16.2�@�d��A���͂����{
16.2.1�@���̓c�[�����g�p���ďd��A���͎��{
�@����X�[�p�[�ŁA�x�X8�X�܂ɂ��Ĕ����̍\���x�E�X���̋���x�E���i�̏]���x�ƓX��1�u������̔���������Ƃ���A���̂悤�Ȍ��ʂ�����ꂽ�B�����ړI�ϗʂƂ��A�����\���x�E�X������x�E���i�[���x������ϗʂƂ��ďd��A���͂����{����B
�����\���x:7�@�X������x:5�@���i�[���x:5�@�̓X�܂�V�K�ɊJ�X����Ƃ���Ɣ���グ��1�u�����肢����Ɨ\������邩�B
(1)���͂���f�[�^����͂���B
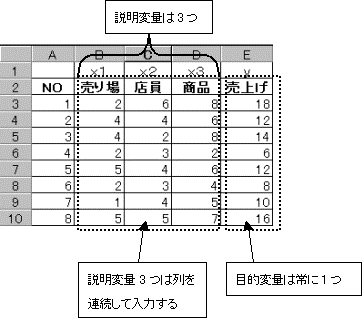
�������ϗʂ���͂��鎞�́A�s�܂��͗�����ɘA�������͈͂ɓ��͂���B
(2)�c�[�������̓c�[����A��I������B
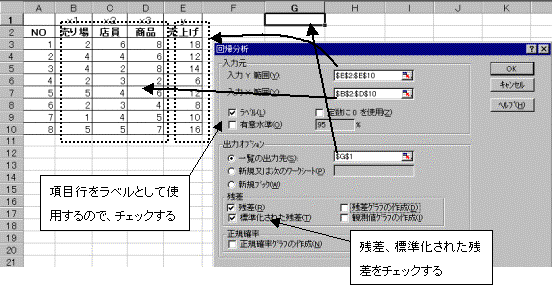
���͔͈�(Y)�͖ړI�ϗʂ͈̔͂ł���B���͔͈�(X)�͐����ϗʂ͈̔͂ł���B�����ł͐����ϗʂ�3��A�����Ă���̂ŁA�����ϗʂ͈̔͂����ׂđ��w�肷��B�Ȃ��A�擪�s�̕��������x���Ƃ��Ďw�肷�̂ŁA���x�����N���b�N���đI�������Ă����B�c���E�W�������ꂽ�c���̗����N���b�N���ă`�F�b�N���Ă����B�S�Ă̐ݒ肪�I��������AOK�{�^�����N���b�N���ĕ��͂��J�n����B
(3)���͌��ʂ�����
(3-1)�d���W���W
|
��A���v |
|
|
�d���� R |
0.98651286 |
|
�d���� R2 |
0.97320763 |
|
� R2 |
0.95311334 |
|
�W���덷 |
0.86613306 |
|
�ϑ��� |
8 |
�d���W��(R):0.98651286�c�ړI�ϗʂƉ�A����苁�߂��\���l�̑��ւ͂��Ȃ荂�����Ƃ��킩��B
�d����W��(R2):0.97320763�c��A�ϓ��̔䗦�����Ȃ荂���A�d��A���͐M����������Ǝv����B
(3-2)���߂��d��A���̐M�����U���͕\�Ŋm�F
|
���U���͕\ |
|
|
|
|
|
|
|
���R�x |
�ϓ� |
���U |
�ϑ����ꂽ���U�� |
�L�� F |
|
��A |
3 |
108.9993 |
36.33308 |
48.43207 |
0.001334 |
|
�c�� |
4 |
3.000746 |
0.750186 |
|
|
|
���v |
7 |
112 |
|
|
|
�ϑ����ꂽ���U��(F)�͎��R�x3,4��F���z�ɏ]���B���ܕ��U��(F):48.43207�ł���A���̊m���l:0.001334�ł���B
��������{
�@����������
�A�������@��A�����͗\���ɖ𗧂��Ȃ�(VR��VE)
�Η������@��A�����͗\���ɖ𗧂@�@(VR��VE)
�A���蓝�v�ʂ����߂�
�@�@�@���蓝�v��(F)=48.43207�́A���R�x3,4��F���z�ɏ]���B
�B�L�m��5%�ŏ�Б���������{
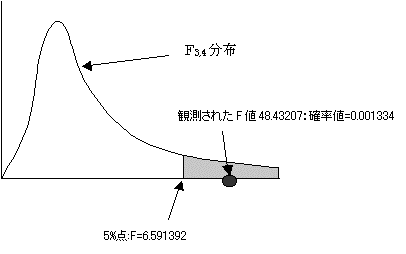
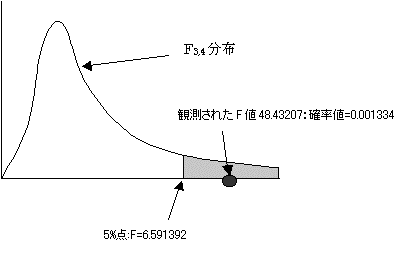
�Ȃ��AF3,4(0.05)�ׂ�ƁA6.591392�ł���B=fdist(0.052,3,4)�ŋ��߂���B
�ϑ��l(F):48.43207��F3,4(0.05):6.591392�ł���A���̎��̊m���l:0.001334��0.05�����������B����Ċ��p��ɓ���B�A�����������p����B��A���͗\���ɖ𗧂Ƃ�����B
(3-3)�Ή�A���̐M�������m�F
|
|
�W�� |
�W���덷 |
t |
P-�l |
���� 95% |
��� 95% |
���� 95.0% |
��� 95.0% |
|
�ؕ� |
-1.3788229 |
1.279866 |
-1.07732 |
0.341975 |
-4.93231 |
2.174662 |
-4.93231 |
2.174662 |
|
����� |
0.11984513 |
0.242232 |
0.494754 |
0.646716 |
-0.5527 |
0.792389 |
-0.5527 |
0.792389 |
|
�X�� |
1.06212482 |
0.289351 |
3.670711 |
0.021378 |
0.258755 |
1.865494 |
0.258755 |
1.865494 |
|
���i |
1.54583881 |
0.197781 |
7.815898 |
0.001446 |
0.996709 |
2.094969 |
0.996709 |
2.094969 |
�e�Ή�A�W����Y�ؕВl��X1:0.11984513�@X2:1.06212482�@X3:1.54583881�@Y�ؕ�:-1.3788229
����ċ��߂�ꂽ�d��A����Y=0.11984513X1+1.06212482X2+1.54583881X3-1.3788229
���Ɋe�����ϗʂ̐M��������������B
�@�����(X1�ϗ�)
t�l:0.494754�@���̎��̊m��:0.646716�D����́u�A������:�����ϗ�X1�͗\���ɖ𗧂��Ȃ��v�����p�ł��Ȃ��B����ĕϗ�X1�Ɨ\���ɖ𗧂Ƃ͂����Ȃ��B
�A�X��(X2�ϗ�)
t�l:3.670711�@���̎��̊m��:0.021378����́u�A������:�����ϗ�X2�͗\���ɖ𗧂��Ȃ��v�����p����B����ĕϗ�X2�͗\���ɖ𗧂Ƃ�����B
�B���i(X3�ϗ�)
t�l:7.815898�@���̎��̊m��:0.001446����́u�A������:�����ϗ�X3�͗\���ɖ𗧂��Ȃ��v�����p����B����ĕϗ�X3�͗\���ɖ𗧂Ƃ�����B
�CY�ؕ�
t�l:-1.07732�@���̎��̊m��:0.341975����́u�A������:Y�ؕЂ͗\���ɖ𗧂��Ȃ��v�����p�ł��Ȃ��B�����Y�ؕЂ͗\���ɖ𗧂Ƃ͂����Ȃ��B
�ȏォ�狁�߂�ꂽ�d��A���͗\���ɖ𗧂Ƃ����邪�A�ϗ�X1(�����̍\���x)��Y�ؕЂ͗\���ɖ𗧂Ƃ͂����Ȃ��B
(3-4)�\���l�Ǝc��������
���͂���f�[�^�ƁA�d��A�����g�p�����\���l�̕\�����킹�Ă݂�Ɖ��̂悤�ȕ\�ɂȂ�B
������f�[�^�ƁA��A�����瓾��ꂽ�f�[�^�̍����c���ł���A�c�����v�Z����ĕ\������Ă���B
|
|
���P |
���Q |
���R |
�� |
|
||
|
NO |
����� |
�X�� |
���i |
���グ |
�\���l: ���グ |
�c�� |
�W���c�� |
|
1 |
2 |
6 |
8 |
18 |
17.6003268 |
0.3996732 |
0.6104350 |
|
2 |
4 |
4 |
6 |
12 |
12.6240898 |
-0.6240898 |
-0.9531944 |
|
3 |
4 |
2 |
8 |
14 |
13.5915178 |
0.4084822 |
0.6238893 |
|
4 |
2 |
3 |
2 |
6 |
5.1389195 |
0.8610805 |
1.3151587 |
|
5 |
5 |
4 |
6 |
12 |
12.7439349 |
-0.7439349 |
-1.1362381 |
|
6 |
2 |
3 |
4 |
8 |
8.2305971 |
-0.2305971 |
-0.3521991 |
|
7 |
1 |
4 |
5 |
10 |
10.7187156 |
-0.7187156 |
-1.0977197 |
|
8 |
5 |
5 |
7 |
16 |
15.3518986 |
0.6481014 |
0.9898683 |
�����\���x(�ϗ�X1):7�@�X������x(�ϗ�X2):5�@���i�[���x(�ϗ�X3):5�@�̎�����͂�����Ɨ\������邩�A���߂��d��A�����g�p���Čv�Z���ċ��߂�B
���߂�ꂽ�d��A��:Y=0.11984513X1+1.06212482X2+1.54583881X3-1.3788229
���̎���X1�X2�X3�̕ϗʂ̐��l����͂���ƁAY=12.4999��12.5�Ƌ��߂���B
1�u������12.5�̔���ƂȂ�ł��낤�B
16.2.2�@�d��A�Ɋւ�������g�p���ďd��A���͂����{
�P��A���͂̎��́A�ړI�ϗʂ͂P�A�����ϗʂ�1�ł������B�������d��A���͂̎��́A�ړI�ϗʂ�1�ł��邪�A�����ϗʂ�2�ȏ�ƂȂ�B�d��A�������߂�ɂ́A�g�p���Ă�������ϗʂ��Ƃ̌W����Y�ؕЂ��K�v�ƂȂ�B
(1)�e�ϗʂ̌W����Y�ؕЁA�d��A���̌�������{������F��linest���g�p
=linest��:=linest(�ړI�ϗʔ͈�,�����ϗʔ͈�,,true)
�@�܂�=linest���ŁA���i(�����ϗ�X3)�̌W�������߂�B
�A�擪�����܂�����A�z���w��
���g�p���Ă�������ϗʂ�3�A����ČW���͐����ϗʂ�3��Y�ؕЂ�1�̌v4�̌W�����K�v�ł��邩��A�z��w��͉�������4�K�v�B�܂��c�����ɂ́A���5�s���͈̔͂��K�v�B����Ĕz��w��͈̔͂́A����4��E�c��5�s���w�肷��B���ɐ����o�[���N���b�N���A�N�e�B�u�ɂ�����ACTRL�L�[+SHIFT�L�[+ENTER�L�[�������Ĕz����������B
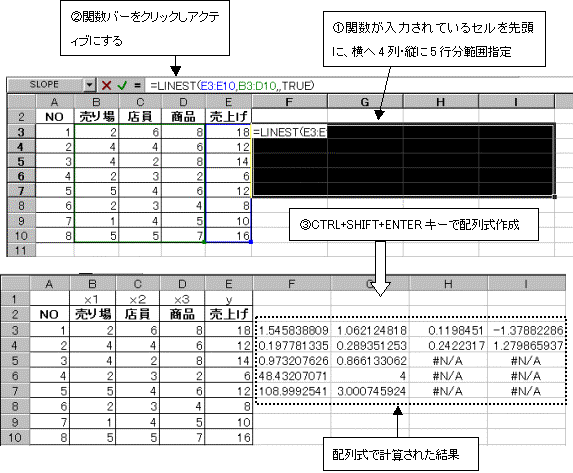
|
X3�W�� |
X2�W�� |
X1�W�� |
Y�ؕ� |
|
1.5458388 |
1.0621248 |
0.11984 |
-1.378822 |
|
|
X2�W���덷 |
X1�W���덷 |
X4�W���덷 |
|
0.1977813 |
0.2893512 |
0.24223 |
1.2798659 |
|
����W�� |
�W���덷 |
|
|
|
0.9732076 |
0.8661330 |
#N/A |
#N/A |
|
���U�� |
�c�����R�x |
|
|
|
48.432070 |
4 |
#N/A |
#N/A |
|
��A�����a |
�c�������a |
|
|
|
108.99925 |
3.0007459 |
#N/A |
#N/A |
�C���ŋ��߂�ꂽ�e�l���A��A���͗p�ɉ��߂���B
1�s�ڂɂ́A�e�����ϗʂ̌W����X3�X2�X1�Y�ؕЂ̏��ɕ\�������B���ꂩ�狁�߂�d��A��:Y=0.11984513X1+1.06212482X2+1.54583881X3-1.3788229�@�����߂���B
����W��(R2):0.9732076
���U��(F):48.432070�@���U��(F)�̎��R�x��2����A�v�Z���ʂ�2�Ԗڂ̎c���̎��R�x���\������Ă���B1�Ԗڂ̎��R�x�́A��A�ϓ�(SR)�̎��R�x�ł���A�����ϗʂ̌�(p)�ł���B���܂�3�g�p���Ă���̂ŁA1�Ԗڂ̎��R�x��3�ł���B2�Ԗڂ̎��R�x�́A�c���ϓ�(SE)�̎��R�x�ł���A�W�{��(n)-�����ϗʌ�(p)-1�ł���B�����4�ƌv�Z����ĕ\������Ă���B�ȏォ��ϑ����ꂽ���U��(F)�͎��R�x3,4��F���z�ɏ]���B����Ɋ����g�p����F3,4(0.05)�����߂�A�㑤5%�_��F�l���킩��̂ŁA���̒l�Ɗϑ����ꂽ���U��(F)���r����悢�BF3,4(0.05)�͊��ł́A=finv(0.05,3,4)�ł���A���̒l��6.591392321���\�������B�܂����U��(F):48.432070�@���R�x3,4�̊m���l�́A=fdist(48.43207,3,4)����0.001334�Ƌ��߂���B�ȏ���܂Ƃ߂Ő}�\�\������Ɖ��̂悤�ȃO���t�ƂȂ�B����͕��̓c�[���ŋ��߂��l�Ɠ����ɂȂ�B
���p��ɓ���̂ŁA��A�ϓ��͌��ʂ��Ȃ������p����B��A�ϓ��͌��ʂ�����B���߂���A���͗\���ɖ𗧂Ƃ�����B
(2)trend���ŗ\���l�����߂�B
trend�����g�p����A�d��A���������I�ɋ��߂āA���̏d��A���ɂ��\���l�����ʂƂ��ĕ\�����Ă����B
trend��:=trend(�ړI�ϗʔ͈�,�����ϗʔ͈�,�萔)�ł��邪�A�����ŖړI�ϗʂ͔͈͎w���f�4�L�[�������āA����W�ɂ���B�܂������ϗʂ͈͎̔w��㓯�l��f�4�L�[�Ő���\������B�萔�͈̔͂́A�����ϗʂ�X1�X2�X3�̐擪�s���w�肷��悢�B���̂悤�ɂ��Ă����A���̂܂܉������Ɍ������ăR�s�[����Ƃ��ׂĂ̗\���l�������ɋ��߂���B


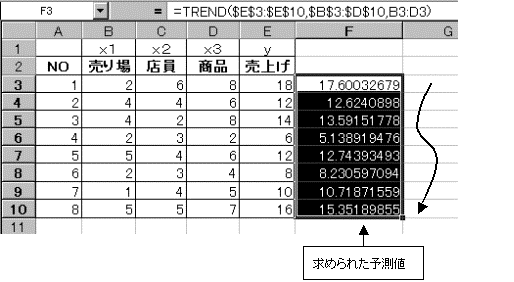
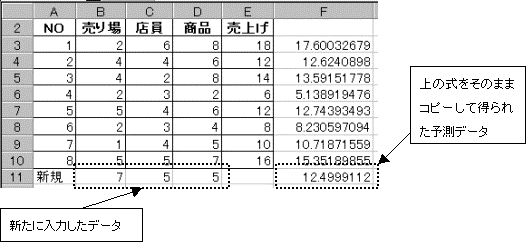 �����\���x:7�@�X������x:5�@���i�[���x:5�@�̎���1�u������̔����\������ɂ́A�����ϗʃf�[�^�̉��̋Ă���s�Ƀf�[�^��X1�X2�X3�̏��ɓ��͂��A��̎��𑱂��Ă��̂܂܉��ɃR�s�[����悢�B���߂�ꂽ���ʂ�12.999112�ł���A���̓c�[���ŋ��߂����ʂƓ����l�邱�Ƃ��ł���B
�����\���x:7�@�X������x:5�@���i�[���x:5�@�̎���1�u������̔����\������ɂ́A�����ϗʃf�[�^�̉��̋Ă���s�Ƀf�[�^��X1�X2�X3�̏��ɓ��͂��A��̎��𑱂��Ă��̂܂܉��ɃR�s�[����悢�B���߂�ꂽ���ʂ�12.999112�ł���A���̓c�[���ŋ��߂����ʂƓ����l�邱�Ƃ��ł���B
16.2.3�@�d��A���͂̑��d������
�����ϗʊԂł��݂��ɍ������ւ�����A���ɂ͕Ή�A�W�������߂邱�Ƃ��ł��Ȃ��Ƃ������ۂ������N�������Ƃ�����B����𑽏d�������Ƃ����B�����ϗʊԂł��݂��ɍ������ւ�����Ƃ������Ƃ́A�ǂ�����������Ƃ�������Ă���ϐ��Ȃ̂ŁA�ǂ��炩����̕ϗʂ�����Ώ[���ł���Ƃ�����B�d��A�������߂�ɂ�����A���d�����������鎞�ɂ͂ǂ��炩�̐����ϗʂ𗎂Ƃ��ċ��߂�K�v������B
(1)���d�������̗L��
���d�����������邩�ǂ����͉��̂悤�ȗv���ׂ�悢�B
�@�����ϗʊԂ̒P���W�������߁A�P���W����1�܂��́|1�ɋ߂����̂�����Α��d���������F�߂���B
�A���d���������F�߂��鎞�ɂ́A�ω�A�W�������߂��Ȃ��Ƃ��A�ω�A�W���̕����Ɛ����ϗʥ�ړI�ϗʊԂ̒P���W������v���Ȃ��Ƃ������ۂ��N�����B
(2)���d�������̗�
�����ϗ�X1�`X3�ƖړI�ϗ�Y�����̂悤�ɂ���Ƃ���B
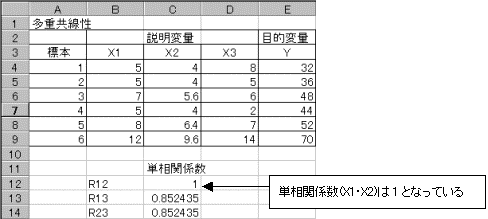 �����ϗ�(X1�`X3)��2�ϗʊԂ̒P���ȑ��W�����u�P���W���v�Ƃ����B���̒P���W��������ϗʊԂŒ��ׂ�B�P���W��(X1�X2):1�@�P���W��(X1�X3):0.852435�@�P���W��(X2�X3):0.852435�@�ƂȂ��Ă���B�P���W��(X1�X2)��1�ƂȂ��Ă���B���̂��Ƃ́A�����ϗ�X1�Ɛ����ϗ�X2�͓�������������Ă���̂ŁA�ǂ��炩����̕ϗʂ��g�p����A�����̕ϗʂ͕s�v�ȕϗʂł���B�ǂ��炩�̕ϗʂ𗎂Ƃ��āA�d��A���͂�����K�v������B
�����ϗ�(X1�`X3)��2�ϗʊԂ̒P���ȑ��W�����u�P���W���v�Ƃ����B���̒P���W��������ϗʊԂŒ��ׂ�B�P���W��(X1�X2):1�@�P���W��(X1�X3):0.852435�@�P���W��(X2�X3):0.852435�@�ƂȂ��Ă���B�P���W��(X1�X2)��1�ƂȂ��Ă���B���̂��Ƃ́A�����ϗ�X1�Ɛ����ϗ�X2�͓�������������Ă���̂ŁA�ǂ��炩����̕ϗʂ��g�p����A�����̕ϗʂ͕s�v�ȕϗʂł���B�ǂ��炩�̕ϗʂ𗎂Ƃ��āA�d��A���͂�����K�v������B
�����ϗ�X2�͐����ϗ�X1��0.8�{�ƂȂ��Ă���B����͂܂�������������������Ă��邱�ƂɂȂ�B
���P���W���́A�����܂ł��P����2�ϗʊԂ̑��W���̂��Ƃł���B�d��A���͂ł́A�g�p���Ă�������ϗʂ̐���2�ȏ�ƂȂ邽�߂ɁA���݂��ɉe���������̂ŁA�P���W����2�ϗʊԂ̊W��\���Ƃ͌���Ȃ��B���ϗʂ�2�ϗʊԂ̐��m�ȊW�����߂�ɂ́A�Α��W�������߂�K�v������B
16.2.4�@�W���Ή�A�W��
�����ϗʂ��ǂꂭ�炢�ړI�ϗʂɉe����^���Ă��邩(��^���Ă��邩)�ׂ�ɂ́A���߂��d��A���̕Ή�A�W��������悢�B�Ή�A�W�����傫���قǖړI�ϗʂɗ^����e�����傫���Ƃ�����B�������A�����ϗʊԂŒP�ʂ��قȂ鎞�ɂ́A�P�ʂ̉e������̂ŁA�P���ɕΉ�A�W���̑召�����߂邱�Ƃ͂ł��Ȃ��B�P�ʂ̉e������菜���ɂ́A�f�[�^��W��������悢�B�f�[�^��W�������邱�Ƃɂ��A����=0�@���U=1�ƂȂ�P�ʂ̉e�����Ȃ��Ȃ�̂ŁA�W���������f�[�^����Ή�A�W�������߂�悤�ɂ���B���̂悤�ɕW���������f�[�^���狁�߂��Ή�A�W�����u�W���Ή�A�W���v�Ƃ����B�W���Ή�A�W�����傫���قǁA�ړI�ϗʂɗ^����e�����傫���A��^�̑傫���ϗʂƂ�����B

��̗��̃f�[�^��W��������Ɖ��̂悤�ȕ\�ɂȂ�B
���̗�ł́A�����ϗʂ̒P�ʂ������ł��邩��A���߂�ꂽ�Ή�A�W�����r���邾���ł悢���A�W�������Ċm�F���Ă݂�B
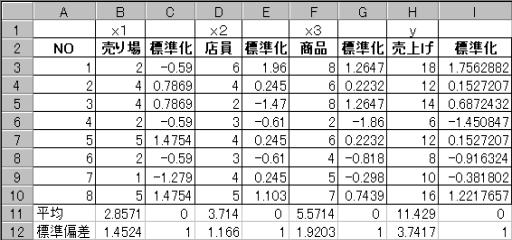
�W���������f�[�^�̂ݔ����o�����āA�V�����\���쐬����

���̕W�������ꂽ�e�f�[�^���g�p���āA�d��A���͂���ƁA�e�Ή�A�W���́A��̂悤�ȕ\�ƂȂ�B���̕W�������ꂽ�Ή�A�W��������ƁA���i�̕Ή�A�W������ԑ傫���A���ɓX���̕Ή�A�W���ƂȂ��Ă���B�����ϗ�X3(���i)�̖ړI�ϗ�(���グ)�^����e������ԑ傫���B
�܂������g�p���āA�W���������Ή�A�W�������߂Ă��������ʂ���
�W�����O�̕ϗ�X1:0.119845132�@X1�̕W������Y�̕W����=0.3881619�@
�W�����������̕ϗ�X1�̌W��:0.119845132�~0.3881619=0.046519
���̐����ϗʂɂ��čs���Ă����l�̌��ʂƂȂ�B