3.判別分析
2群以上の母集団から抽出した標本データを得て、いまどの母集団に属するか不明のサンプルデータがあるとする。このサンプルデータがどの母集団に属するか調べる方法に、判別分析がある。判別分析を実施するには、集めた標本がどの母集団に属しているのかをあらかじめ区分けしておく必要がある。区分けする方法に、線形判別式を使用する方法と、マハラノビスの距離を用いる方法がある。
3.1 線形判別式を使用する方法
多変量データx1・x2…xn があるとする。この説明変量x1・x2…xn はいずれも量的データであり、この変量に適当な重みa1・a2…an をつけ目的変量Zを得る。
Z=a1・x1+a2・x2+…+an・xn+a0
この時得られる目的変量Zが区分わけを示す質的データであるとき、この式を線形判別式という。重回帰式では、説明変量も目的変量も量的データを扱ったが、判別分析においては、説明変量は量的データであるが、得られる目的変量はどの母集団に属するのか示す質的データを扱う。
いま、A中学校の8人の生徒の英語(x1)と数学(x2)の評価があり、この8人の生徒がB高校を受験してその合否結果(Z)が分かっているとする。すると、ここに2つの母集団、合格群と不合格群があることになる。
|
NO |
説明変量 英語(x1) 数学(x2) |
目的変量(Z) 合 否 |
|
1 2 3 4 5 6 7 8 |
5 8 5 5 7 4 8 5 7 2 4 3 8 7 4 6 |
合 否 合 合 否 否 合 否 |
|
平均 |
6 5 |
|
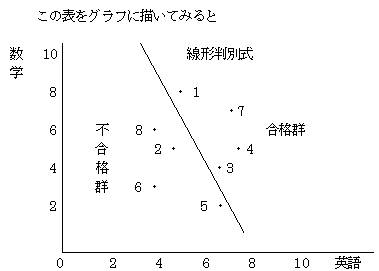
合格した群(1・3・4・7)と不合格の群(2・5・6・8)を区分わけする直線を1本考える。
この直線が、線形判別式となる。この線形判別式が判明すれば、どの母集団に付属するのか不明のサンプルデータの所属を得ることができる。
3.1.1 線形判別式を求める。
説明変量が2つあるのでこれをx1・x2 とすると、この判別式を
Z=a1・x1+a2・x2+a0 とする。
合格した群をA群、不合格の群をB群とすると、この判別式Zは、2群(A群とB群)から最も遠い位置に引かれる必要がある。2群から最も遠い位置に引かれることにより、この判別式は、2群A・Bを区分けする最も良い基準線となる。
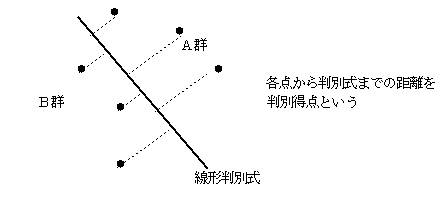
(1)判別得点を求める
判別得点は、各標本データ点から判別式までの距離で表される。
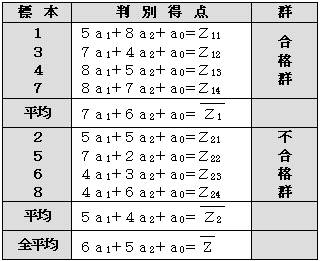
もとの標本を合格した群と不合格の群に分けて整理すると
|
NO |
説明変量 英語(x1) 数学(x2) |
目的変量(Z) 合 否 |
|
|
1 3 4 7 |
5 8 7 4 8 5 8 7 |
合 合 合 合 |
A 群 |
|
平 均 |
7 6 |
|
|
|
2 5 6 8 |
5 5 7 2 4 3 4 6 |
否 否 否 否 |
B 群 |
|
平 均 |
5 4 |
|
|
|
全平均 |
6 5 |
|
|
説明変量x1・x2は量的データであり、目的変量Zは区分を示す質的データである。
通常量的データ間の関係を表すものとしては相関係数があるが、量的データと質的データの関係を表すものとして相関比(η)がある。相関比(η)は
η2=級間変動÷全変動
で与えられる。
それぞれの標本について判別得点を求める。
2群を最もよく分けるには、全変動をST 級間変動をSBとするとき、相関比(η2)を最大にするようにする。
全変動STは、全平均Zから各々のデータがどれ位散らばっているかである。
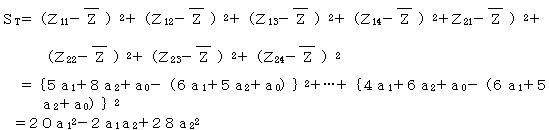
級間変動SBは、A群の平均が全平均からどの位散らばっているかと、B群の平均が全平均からどの位散らばっているかを合計したものである。
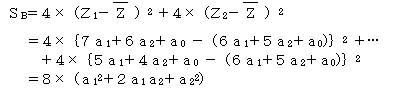
(2)相関比を求める

t=1.381,−1 で相関比η2は最大値または最小値を持つ。このtの値を相関比η2に代入するとt=−1の時 η2=0 となり最小となる。t=1.381の時 η2=0.71556 となり最大となる。つまり相関比η2は、a1÷a2=−1の時最小となり、a1÷a2=1.381の時最大となる。いま求めようとしているのは、相関比η2を最大とするa1・a2であるから、1.381を採用する。
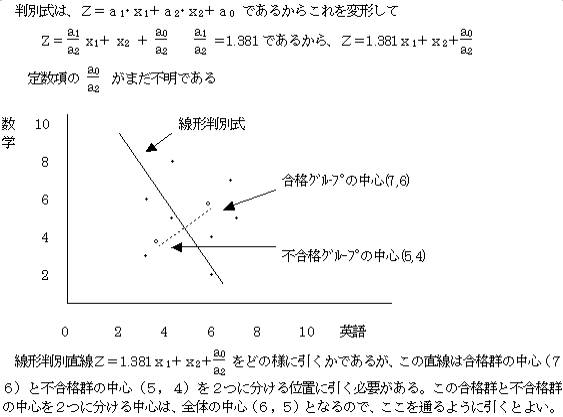

これより求める線形判別式は、Z=1.381x1+x2−13.286 となる。この線形判別式を使用することにより、データを2群に分けることができる。
実際に判別得点を求めて表にしてみると
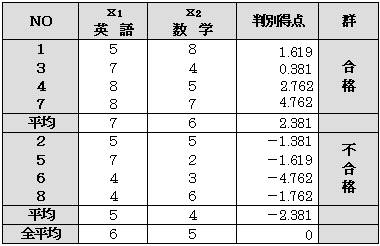
判別得点を見ると、合格群は+ 不合格群は−に群分けされていることが分かる。
以上から、グラフを描いてみると
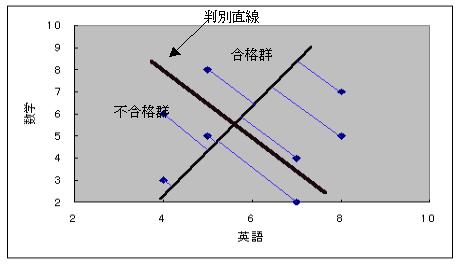
判別直線を境にして、右側に合格群、左側に不合格群があることが分かる。
また全平均(6、5)を通り判別直線に直行する直線を1本引き、その直線上に各点から降ろした点を見ると、全平均(6、5)を新たな原点と考えると上側(+側)に合格群、下側(−側)に不合格群がありその距離が判別得点となっていることが分かる。
3.1.2 分散・共分散行列を用いて判別式を求める。(不偏分散を使用する)
(1)説明変数が2個の時
判別式
Z=a1・x1+a2・x2+a0 を求めるのに分散共分散行列を利用して求める方法がある。いま説明変量がx1・x2と2つあり、A群・B群の2群に分かれている。
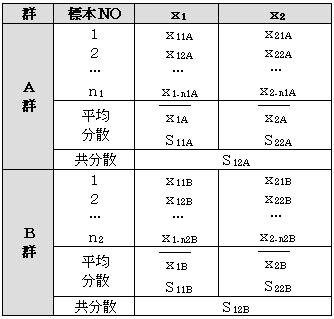
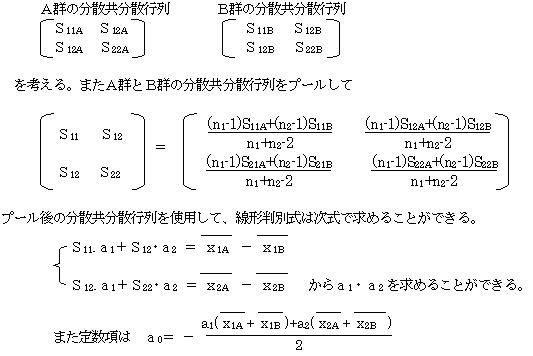
いまA群・B群が上の様になっているとき
(2)説明変量がp個ある時に2A群・Bに分けるとき
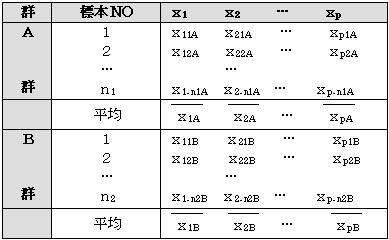
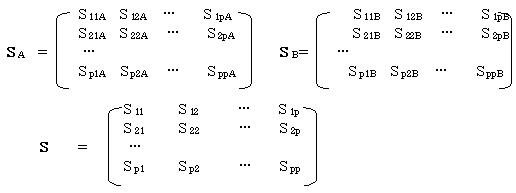
この時、A群の分散共分散行列をSA、B群の分散共分散行列をSB
プール後の分散共分散行列をSとすると

3.2 ボックスM検定
線形判別式を使用して2群を区分わけできるのは、母分散共分散行列が等しい時に限られる。2群の母分散が等しい時には、その判別式は直線になるが、等しくない時には判別式は曲線となる。母分散共分散行列が等しくない時には、マハラノビスの距離による判別を行う必要がある。母分散共分散行列が等しいかどうかの検定に「ボックスM検定」がある。
「ボックスM検定」
A群・B群のそれぞれの分散共分散行列をSA・SBとする。またSA・SBのプール後の分散共分散行列をSとすると

p:説明変量の個数 nA:A群の標本数 nB:B群の標本数
自由度 p(p+1)/2のχ2 分布に漸近的に従う。これを利用して検定を行う。
(1)仮説をたてる
帰無仮説 H0 :2群の母分散共分散行列は等しい
対立仮説 H1 :2群の母分散共分散行列は等しくない
(2)検定統計量χ2は自由度p(p+1)/2のχ2 分布に従う。
(3)有為水準をαとすると
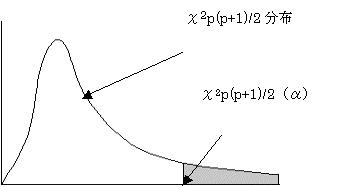
χ2 > χ2p(p+1)/2(α)であれば仮説を棄却する。つまり、2群の母分散共分散行列は等しくない。よってマハラノビスの距離による判別処理をする方が望ましい。
3.3 マハラノビスの距離による判別
3.3.1 マハラノビスの距離
(1)1変量時のマハラノビスの距離
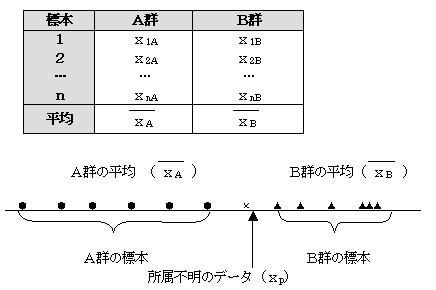
1変量のデータA群とB群が上の様に分布しているとする。A群のデータは分散の大きいデータ群、B群のデータは分散の小さいデータ群である。この時所属不明のデータxpがある時、この所属不明のデータxpがA群、B群のどちらに所属するデータであるか調べる
単純にxpからそれぞれの群の中心までの距離を見ると、明らかにこのxpはB群の中心に近い。![]() となっていので、このxpはB群のデータであるように思える。しかしA群は分散の大きいデータ群であり、B群は分散の小さいデータ群である。この分散を考慮しないで、単純に距離だけでどちらの群に所属するのかを判断することはできない。この分散を考慮した距離に「マハラノビスの距離」がある。
となっていので、このxpはB群のデータであるように思える。しかしA群は分散の大きいデータ群であり、B群は分散の小さいデータ群である。この分散を考慮しないで、単純に距離だけでどちらの群に所属するのかを判断することはできない。この分散を考慮した距離に「マハラノビスの距離」がある。
1変量時のマハラノビスの距離をD2とすると、
![]()
このように分散を考慮すれば、分散の大きいデータほどマハラノビスの距離は小さくなり、 逆に分散の小さいデータほどマハラノビスの距離は大きくなる。

DA2<DB2 であればxpは、A群に近い。DA2>DB2であればxpは、B群に近い。
(2)2変量時のマハラノビスの距離
2変量のデータがA群・B群の2群に分かれているとする。
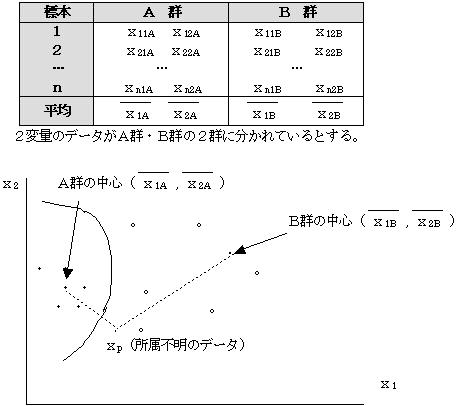
A群は分散の小さいデータ群、B群は分散の大きいデータ群とする。この時所属不明のデータxp(x1,x2)がある時、このデータxpはA群・B群のどちらに所属するデータであるか調べる。
単純な距離を考えると、xpからA群への距離は![]() であり、xpからB群への距離は
であり、xpからB群への距離は![]() である。一見してこのデータxpは、A群に近そうである。しかしA群は分散の小さいデータ群であり、B群は分散の大きいデータ群であるので、分散を考慮しない単純な距離だけでは判断することはできない。次に、分散を考慮したマハラノビスの距離を考えると
である。一見してこのデータxpは、A群に近そうである。しかしA群は分散の小さいデータ群であり、B群は分散の大きいデータ群であるので、分散を考慮しない単純な距離だけでは判断することはできない。次に、分散を考慮したマハラノビスの距離を考えると
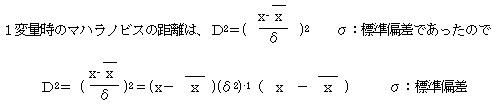
これを2変量について考えと、 1変量から2変量になったので

同様にして変量p個の時のマハラノビスの距離は
マハラノビスの距離は、各群の中心からその標本への分散を考慮した距離を示すので、その標本はマハラノビス距離の小さい方の群に所属する標本であるとする。
3.4 多変量における2群の母平均の差に関する検定
3.4.1 2群間の母平均に差があるかどうか検定を行う。
いま2群がそれぞれN(μ1,σ2)・N(μ2,σ2)に従うとき、ここからn1個・n2個の標本を得たとする。この時2群の母平均μ1=μ2であるかどうか検定は
検定統計量をFとすると
![]()
ただしp:説明変量の個数 D2:2群の中心間のマハラノビスの汎距離
は自由度p,n1+n2−p−1のF分布に従う。これを利用してp変量の2群の母平均の差の検定を行う
(1)仮説をたてる
帰無仮説
H0:μ1=μ2 (2群の母平均は等しい)
対立仮説
H1:μ1≠μ2 (2群の母平均は等しくない)
(2)検定統計量Fは自由度p,n1+n2−p−1のF分布に従う
(3)有為水準αで検定をおこなう
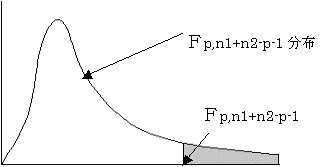
F>Fp,n1+n2−p−1(α)であれば仮説H0を棄却する。つまり2群の母平均に差があるとする。
3.4.2 ウィルクスのΛ(ラムダ)統計量
多変量時の群間の変動を示す量として、ウィルクスのΛ統計量がある。
2群の多変量データが下の表のようにあるとすると
|
群 |
変量 標本 |
X1 X2 … Xp |
|
A 群 |
1 2 … n1 |
X11A X21A … Xp1A X12A X22A … Xp2A … X1・n1A
X2・n1A … Xp・n1A |
|
B 群 |
1 2 … n2 |
X11B X21B … Xp1B X12B X22B … Xp2B … X1・n2B
X2・n2B … Xp・n2B |
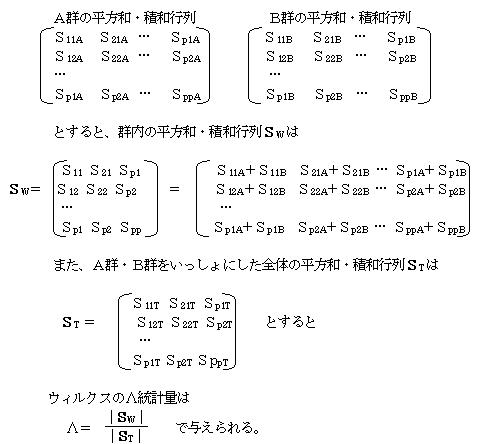
Λ統計量は、0≦Λ≦1の値をとり、Λが0に近いほど2群間の差が大きく、Λが1に近づくほど2群間の差が小さくなる。
このΛ統計量を使用して、2群間の母平均の差の検定をすることができる。
2群p変量の母平均をそれぞれμiA・μiBとすると、μiA=μiBの仮定下で
検定統計量をFとすると、

上記検定統計量Fを使用して、有為水準αで仮説H0:μiA=μiB i=1,2…p を検定し、もしF≧Fp,n−p−1(α)であれば仮説を棄却し、2群の母平均に差があるとする。
3.5 判別分析の的中率
判別分析を実施して所属する群を判別したとき、その標本が本当に所属している母集団と正しく判定されたかどうかの精度を計るものに判別的中率がある。
判別的中率=(正しく判別された標本÷全標本の数)×100 である。
3.6 誤判別の確率
母集団が2つある時、ある標本を間違った母集団からの標本であると判定する誤りの確率を誤判別の確率という
標本が2A群・Bに分かれており、その説明変量がp個ある時、A群の説明変量の平均をx1A・x2A…xpA、またB群の説明変量の平均をx1B・x2B…xpB とする。この時、A群の中心からB群への中心へのマハラノビスの距離D02 は
![]()
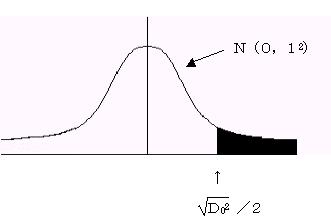
![]() は標準正規分布N(0,12)に従うので、これから誤判別の確率を求める。
は標準正規分布N(0,12)に従うので、これから誤判別の確率を求める。
いまP1をA群の標本であるにもかかわらず、B群の標本であると判定する間違いの確率。 またP2をB群の標本であるにもかかわらず、A群の標本であると判定する間違いの確率とすると誤判別の確率は、P1=P2=標準正規分布の![]() 値の上側確率である。
値の上側確率である。
3.7 説明変量の寄与
線形判別式を、Z=a1x1+a2x2+…+anxn+a0とする。この時係数aiが、判別式に寄与しているかどうか調べる。もし寄与していないのであれば、その説明変量はなくても判別結果に影響を与えていないので、線形判別式から落としてもよい係数である。
2A群・Bで説明変量がp個ある時、下の表のようであるとする。
|
群 |
標本NO |
x1 x2 … xp |
|
A 群 |
1 2 … n1 |
x11A x21A … xp1A x12A x22A … xp2A … x1・n1A x2・n1A … xp・n1A |
|
B 群 |
1 2 … n2 |
x11B x21B … xp1B x12B x22B … xp2B … x1・n2B x2・n2B … xp・n2B |
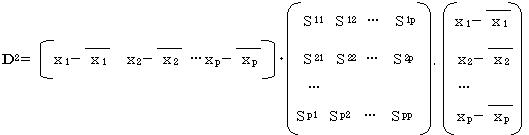
D2P :P個の変量を使用した2群の中心間のマハラノビスの距離。D2P-1:P個の変量からある特定の変量を1つ落としたときの2群の中心間のマハラノビスの距離 とすると ![]()
のでこれを利用して係数の有用性の検定を行う。
検定を行う
(1)仮説をたてる
帰無仮説 H0:ai=0 (係数aiは役にたたない)
対立仮説
H1:ai≠0
(2)検定統計量Fは自由度1,n1+n2−p−1のF分布に従う。
(3)有為水準αで検定を行う
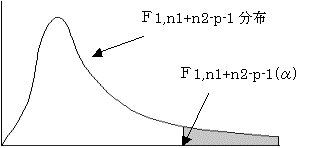
F>F1,n1+n2−p−1(α)であれば、仮説H0を棄却する。つまり係数aiは判別式に寄与しているといえる。
判別式に寄与していない係数は、使用しなくても結果に影響を与えていないので不必要な変量であるといえるので、その係数は削除しても構わない。
この係数の寄与についてのF値を使用することにより、重回帰式と同様に変数選択の前進選択法・後退減少法ならびに変数増減法などの変数選択を実行することができる。
3.8 よい判別式を作成する。
判別式では、いくつかの量的データである説明変量から区分わけを示す質的データである目的変量を得る。この時重回帰式と同様に説明変量をむやみに多くしても無駄なことが多い。よい判別式は、少ない説明変量で精度の高い区分わけができるような式である。このために説明変量を調べ、判別式に必要な変量であるかどうか検討する必要がある。
3.8.1 説明変量選択の基準
(1)目的変量に与える影響の大きい説明変量を選ぶ。
重回帰分析では、説明変量・目的変量ともに量的データであるので、その関係は相関係数で調べることができたが、判別分析では説明変量は量的データで目的変量は質的データで ある。このように量的データと質的データ間の関係を調べるには相関比(η)を使用する。
なお、相関比(η)は、0≦η≦1の値をとり、1に近いほど級間変動が大きく2変量間の関係が強いといえる。
いま説明変量がいくつかあり、その中の1つの変量xが2A群・Bに分かれているとする。この時の相関比を求める。
相関比の2乗(η2)は
η2=級間変動÷全変動 で与えられる。
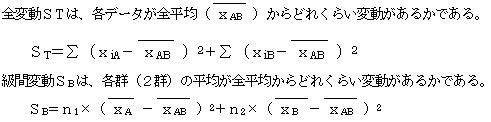
これから相関比(η2)=SB÷STが求められる。
各変量について相関比を求め、相関比の大きい変量ほど目的変量に与える影響が大きいといえるので積極的に判別式に採用する。
[相関比に関する検定]
変量x1…xpがお互いに独立であり、ともに正規分布に従うものとする。
(1)仮説をたてる
帰無仮説
H0:η0=0
(母相関比=0)
対立仮説
H1:η0≠0
(母相関比≠0)
(2)検定統計量をFとする

(3)有為水準αで検定する
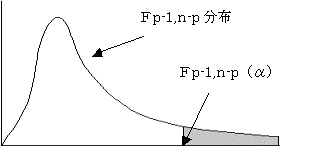
F≧Fp−1,n−p(α)であれば、仮説を棄却する。つまり母相関比≠0とする。
(2)説明変量間でお互いに高い相関がある時には、どちらかの変量を落とす。説明変量間の相関については、単相関係数を用いて調べる。これは重回帰式と同様に説明変量間でお互いに高い相関があるときには、多重共線性を示すからである。お互い高い相関がある変量は、同じことを説明しているので、どちらか一方の変量を落としても目的変量に与える影響は小さく、判別結果に差異はないといえる。

「係数aiの符号」と「2群の平均の差の符号」を見れば、多重共線性が分かる。
3.8.2 判別式における変数選択法
重回帰式の時と同様に、判別式においても説明変量選択の方法がある。
説明変量の選択の方法には、重回帰式同様「変数増加法」「変数減少法」「変数増減法」「変数減増法」などがあり、これらの方法を重回帰式の時と同じように行う。
変量採否の基準としては、説明変量の寄与での係数aiのF値を検討しながら行う。